DDIA 第一版精炼:数据系统的可靠性、扩展性与正确性
《Designing Data-Intensive Applications》不是一本教你怎么用某个数据库的书。它更像是一套数据系统的判断框架:什么时候该用关系模型,什么时候文档模型更顺;为什么 LSM-tree 写入快,B-tree 更稳;复制延迟会让用户看到什么怪现象;事务到底帮应用屏蔽了哪些并发问题;共识为什么难,又为什么绕不开。
这篇文章整理自 DDIA 第一版英文原文。我会把全书压缩成一份可以连续阅读的学习版资料,保留主线、术语、关键例子和工程权衡,但不会复刻原书的长篇展开。
0. 材料定位
《Designing Data-Intensive Applications》(后文简称 DDIA)不是一本教你使用某个数据库的书。它讲的是:当应用主要瓶颈不再是 CPU,而是数据量、数据复杂度、数据变化速度和系统协作复杂度时,工程师该如何理解数据系统。
原书有三条贯穿全书的目标:
- 可靠性:系统在硬件、软件、人为错误和网络故障下仍尽量正确工作。
- 可扩展性:负载、数据量和复杂度增长时,系统仍有合理的应对办法。
- 可维护性:系统能被人理解、运维、演化,而不是变成无法修改的遗留泥球。
全书结构分三部分:
- Part I Foundations of Data Systems:单机和基础数据系统,包括数据模型、存储引擎、编码与演化。
- Part II Distributed Data:分布式数据,包括复制、分区、事务、分布式故障、一致性和共识。
- Part III Derived Data:派生数据,包括批处理、流处理,以及未来数据系统的整合方向。
本文采用中度微压缩。会保留必要例子,例如 Twitter 时间线、LinkedIn 简历模型、LSM-tree、购物车并发写、医生值班 write skew、网络请求不确定性、ZooKeeper、Unix 管道、Kafka 风格日志和派生数据系统。
1. 全局知识地图
DDIA 的主线可以压缩成一句话:
数据密集型应用的核心,是在不断变化、不断失败、不断增长的数据世界里,用合适的抽象把复杂性控制在工程师能理解和系统能承受的范围内。
全书的知识依赖如下:
| 层次 | 核心问题 | 对应章节 |
|---|---|---|
| 系统目标 | 什么样的数据系统算可靠、可扩展、可维护? | 第 1 章 |
| 数据表达 | 用关系、文档、图,还是其他模型表达业务? | 第 2 章 |
| 数据存取 | 数据落到磁盘后,数据库如何高效写入和查询? | 第 3 章 |
| 系统演化 | 数据格式、服务 API、消息如何兼容新旧版本? | 第 4 章 |
| 数据副本 | 多个副本如何保持同步?延迟会带来什么异常? | 第 5 章 |
| 数据拆分 | 数据太大时如何分区、重平衡、路由请求? | 第 6 章 |
| 并发正确性 | 事务到底屏蔽了哪些错误?隔离级别差在哪里? | 第 7 章 |
| 分布式现实 | 网络、时钟、进程暂停为什么不可靠? | 第 8 章 |
| 强保证 | 线性一致性、因果性、共识分别解决什么? | 第 9 章 |
| 离线派生 | 批处理如何把大规模有界输入转成派生数据? | 第 10 章 |
| 连续派生 | 流处理如何处理无界事件、状态和故障? | 第 11 章 |
| 系统未来 | 如何用日志、派生数据、端到端正确性组合系统? | 第 12 章 |
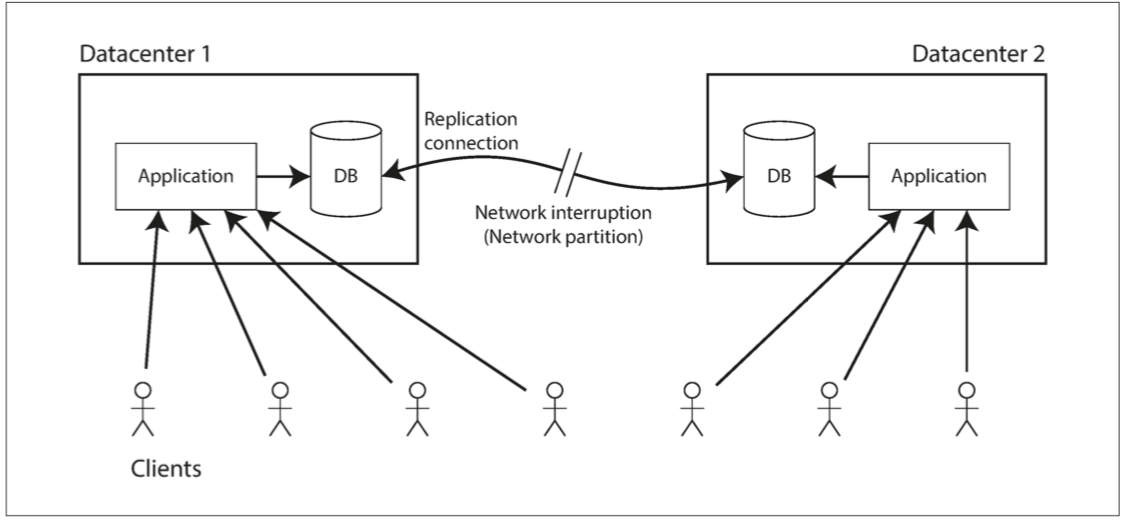
推荐对照图片:


2. 精炼学习正文
第 1 章:可靠、可扩展、可维护的应用
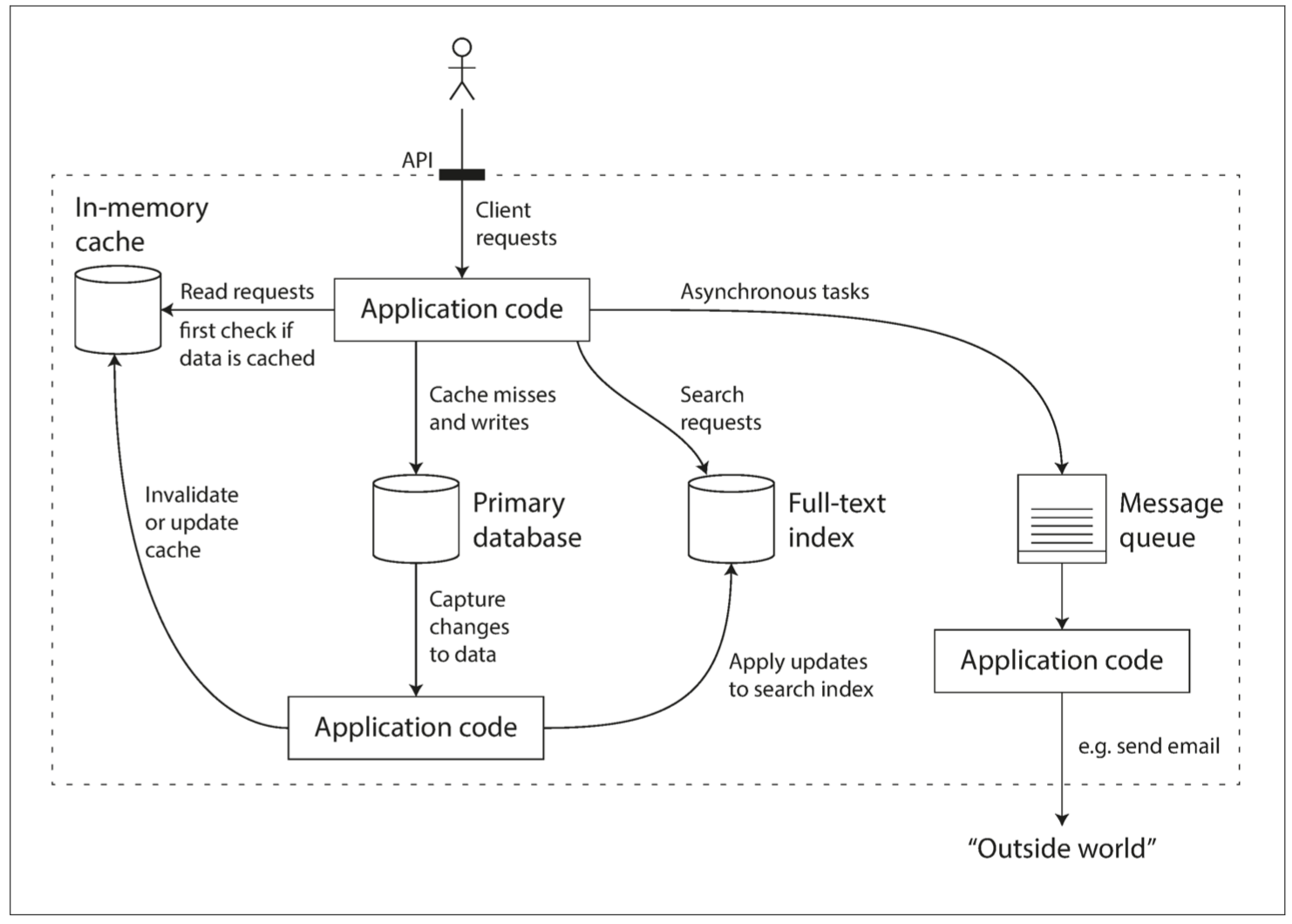
本章建立全书的判断标准。现代数据密集型应用通常不是 CPU 算不动,而是数据太多、变化太快、表示太复杂、系统组件太多。一个应用往往同时使用数据库、缓存、搜索索引、消息队列、批处理和流处理。当应用把多个通用工具组合起来,并对外提供一个统一 API 时,开发者其实已经在设计一个新的专用数据系统。
可靠性指系统在出错时仍继续正确工作。这里要区分 fault 和 failure:fault 是某个组件偏离预期,failure 是系统整体不能向用户提供服务。可靠系统的目标不是消灭所有 fault,而是防止 fault 放大成用户可见的 failure。
故障来源包括硬件、软件和人。硬件故障在大规模机器集群里是常态,例如磁盘损坏、电源故障、机器宕机。软件错误更危险,因为它往往是系统性和相关性的:同一个 bug 可能让所有节点在相同输入下同时崩溃。人为错误也很常见,尤其是配置错误、错误操作和发布问题。可靠系统需要测试、监控、隔离、回滚、灰度发布和自动化恢复。
可扩展性不是一句“这个系统可扩展”。正确问法是:如果负载以某种方式增长,我们有哪些选择?负载要用具体参数描述,例如请求数、读写比例、活跃用户数、数据量、热点 key 数量、扇出规模。性能也要量化,尤其是响应时间分位数,而不只是平均值。平均值会掩盖尾延迟;一个请求如果依赖多个后端调用,只要其中一个慢,整个用户请求就慢,这就是尾延迟放大。
可维护性分成三件事:
- 可运维性:系统要让运维人员容易观察、恢复、升级和管理。
- 简单性:通过抽象消除偶然复杂性,而不是堆砌功能。
- 可演化性:需求变化、平台变化、规模变化时,系统能被修改。
这一章的作用是给后文所有技术做评价标准。复制、分区、事务、共识、批处理、流处理都不是孤立技巧,它们都是为了在不同约束下实现可靠性、可扩展性和可维护性。
学习检查:
- 为什么“可扩展”必须先定义负载参数?
- fault 和 failure 有什么区别?
- 为什么系统性软件错误比单机硬件错误更危险?
- 为什么响应时间要看高分位数?
第 2 章:数据模型与查询语言
数据模型影响的不只是代码怎么写,还影响我们如何思考问题。应用开发者把现实世界建模成对象或数据结构,再把这些结构存进关系表、文档、图或其他通用数据模型。数据库内部又把这些模型编码成磁盘和内存中的字节。每一层模型都隐藏下一层复杂性,也限制上一层能自然表达什么。
关系模型把数据组织成表和行。它的优势是通用、成熟、能表达多对多关系,并且查询语言 SQL 是声明式的。关系模型最初服务商业数据处理,但后来广泛适应了 Web、社交、电商、游戏和 SaaS 等场景。
文档模型适合自包含、一对多树状结构的数据。原书用 LinkedIn 简历说明:一个用户有多个职位、教育经历和联系方式,JSON 文档能把整个简历放在一起,读一个用户资料时局部性很好,应用对象和存储结构也更接近。
但文档模型在多对一和多对多关系上会变麻烦。比如地区、行业、学校、组织、推荐人都可能从普通字符串演化成实体引用。一旦关系变多,应用要么复制数据,要么自己做 join。历史上层级数据库也遇到过类似问题,后来关系模型正是为了解决多对多和查询灵活性而崛起。
关系数据库和文档数据库没有绝对胜负。判断标准是数据形状和访问模式:
- 数据主要是树状、整体读取、内部关系紧密:文档模型可能简单。
- 数据之间关系多、需要 join、需要灵活查询:关系模型更自然。
- 任意实体之间都可能连接,并且查询重点是沿关系遍历:图模型更合适。
图模型适合高度互联的数据。属性图把数据表示为顶点、边和属性;Cypher 用模式匹配查询图。三元组存储把所有事实表示为 subject、predicate、object;SPARQL 查询三元组;Datalog 用规则推导新关系。图查询语言的重要价值是让复杂路径查询更自然,而不是把递归 join 硬塞进 SQL。
查询语言也有重要差异。声明式查询语言让用户描述“想要什么”,由系统决定“怎么做”。SQL、Cypher、SPARQL 都体现了这一点。声明式语言更容易被优化器重写、并行化和优化。命令式查询虽然控制力强,但更容易把执行策略写死。
学习检查:
- 文档模型为什么适合一对多树结构?
- 多对多关系为什么会削弱文档数据库优势?
- 声明式查询语言为什么有利于优化?
- 图数据库和 CODASYL 网络模型有什么本质差异?
第 3 章:存储与检索
数据库最基本的任务是:写入数据,后来再找回来。应用开发者即使不写存储引擎,也需要理解底层原理,因为不同存储引擎适合不同工作负载。
本章从一个极简 key-value 数据库开始:写入时只追加到文件尾部,读取时扫描整个文件找最后一次出现的 key。追加写很快,读取很慢。要让读取变快,就需要索引。索引是从主数据派生出来的额外结构,它能加速读,但会拖慢写,因为每次写入也要更新索引。
第一类存储引擎是日志结构。最简单形式是追加日志加内存 hash index。每个 key 映射到文件偏移,读时用 hash map 定位。为了防止日志无限增长,需要把日志分段,对旧段做压缩和合并,只保留每个 key 的最新值。删除用 tombstone 标记。追加写、不可变段、后台合并让崩溃恢复和并发控制更简单。
Hash index 的限制是 key 必须放进内存,并且不适合范围查询。SSTable 通过让段内 key 有序来解决这些问题。SSTable 只需要稀疏索引,就能用有序性定位范围;多个 SSTable 可以像归并排序一样合并。写入先进入内存有序结构 memtable,memtable 达到阈值后刷成 SSTable。为了崩溃恢复,还要保留预写日志。这套思想形成 LSM-tree,被 LevelDB、RocksDB、Cassandra、HBase、Lucene 等系统使用。
第二类存储引擎是 B-tree。B-tree 把磁盘分成固定大小页,索引页保存 key 范围和子页指针,叶子页保存记录位置或记录本身。B-tree 更新是就地修改页,因此需要 WAL 保证崩溃恢复。B-tree 很成熟,广泛用于关系数据库。它通常读性能稳定,适合范围查询;但随机写和页分裂会带来写放大。
LSM-tree 与 B-tree 的核心权衡:
- LSM-tree 把随机写转成顺序写,写吞吐通常更好。
- LSM-tree 读取可能要查多个段,需要 Bloom filter 和合并策略优化。
- LSM-tree 后台压缩会竞争磁盘资源,压缩跟不上会造成问题。
- B-tree 读路径直接、范围查询强,但写入更随机。
后半章区分 OLTP 和 OLAP。OLTP 面向用户请求,单次查询通常访问少量记录,瓶颈常是磁盘寻址和索引查找。OLAP 面向分析,单次查询扫描大量行但只用少数列,瓶颈常是磁盘带宽和 CPU 内存带宽。因此数据仓库常用列式存储:每列单独存储,只读取查询需要的列。列式存储还适合压缩,例如位图编码和运行长度编码。
星型模式是数据仓库常见模型:事实表记录事件,维度表描述日期、产品、门店、用户等上下文。物化视图和数据立方体通过预计算聚合提高查询速度,但会降低灵活性并增加写入维护成本。
学习检查:
- 为什么索引会加速读但拖慢写?
- LSM-tree 如何把随机写转成顺序写?
- B-tree 为什么需要 WAL?
- OLTP 和 OLAP 的访问模式有什么根本差异?
- 列式存储为什么适合分析查询?
第 4 章:编码与演化
系统会不断演化。新增字段、修改格式、升级服务都要求旧代码和新代码共存。滚动升级让一部分节点先运行新版本,另一部分仍运行旧版本;客户端应用也可能长期停留在旧版本。因此数据格式必须支持两种兼容性:
- 向后兼容:新代码能读旧数据。
- 向前兼容:旧代码能读新数据,至少能忽略不认识的新增字段。
程序内存中的对象不能直接写入文件或发到网络,因为指针、对象布局和语言运行时只在本进程内有意义。编码是把内存数据转成字节序列;解码是从字节恢复数据结构。
语言自带序列化通常不适合长期数据和跨服务协议。它们绑定语言,兼容性弱,安全风险高,性能也可能差。JSON、XML、CSV 更通用、人可读,但有数字精度、二进制数据、schema 模糊等问题。二进制格式更紧凑,但如果只是把 JSON 变成二进制并保留字段名,收益有限。
Thrift、Protocol Buffers 和 Avro 代表 schema 驱动的二进制编码。Thrift 和 Protobuf 用字段 tag 代替字段名,所以新增字段只要使用新 tag,旧代码就能跳过未知字段。字段 tag 不能随便改,因为已有数据依赖 tag 含义。Avro 的特点是 writer schema 和 reader schema 分离,读取时按字段名匹配,并通过 schema resolution 处理差异。Avro 很适合数据文件和动态生成 schema 的场景。
编码格式不仅影响存储,也影响数据流动方式。原书讨论三类 dataflow:
- 通过数据库流动:一个进程写入编码数据,另一个进程后来读取。
- 通过服务流动:客户端编码请求,服务端解码并编码响应。
- 通过消息传递流动:生产者编码消息,消费者解码消息。
RPC 试图把远程调用伪装成本地函数调用,这是危险抽象。网络请求可能超时、丢失、重复、变慢;调用方不知道请求没到、响应丢了,还是对方已经处理但响应没回来。重试可能造成副作用重复。因此远程调用不应被设计得像普通本地函数一样透明。REST 的优势之一恰恰是没有完全隐藏网络协议本质,易调试、生态广。
消息队列介于 RPC 和数据库之间。它像 RPC 一样低延迟传递消息,也像数据库一样暂存消息。消息 broker 能缓冲、重投、扇出、解耦发送者和接收者。只要消息编码支持向前和向后兼容,生产者和消费者就能独立升级。
学习检查:
- 为什么滚动升级要求双向兼容?
- Protobuf 的字段 tag 为什么不能随便改?
- Avro 的 writer schema 和 reader schema 解决了什么问题?
- 为什么 RPC 的“位置透明性”是危险抽象?
第 5 章:复制
复制是把同一份数据保存在多个节点上。它的目的包括:提高可用性、让数据靠近用户、扩展读吞吐、支持离线操作。复制本身不难,难的是复制持续变化的数据。
单领导者复制中,所有写入先到 leader,再通过复制日志发送给 follower。读可以从 leader 或 follower 读取,但 follower 可能滞后。同步复制能保证 follower 收到后再确认写入,但如果同步 follower 挂了,写入会阻塞。异步复制延迟低、可用性好,但 leader 故障时可能丢失已经向客户端确认但尚未复制的写入。
leader 故障需要 failover:判断 leader 死亡、选新 leader、让客户端切到新 leader、让旧 leader 回来后承认新身份。这一步风险很高。异步复制可能导致新 leader 缺少旧 leader 上的写入;旧 leader 恢复后可能出现 split brain;过短 timeout 会误判故障,过长 timeout 会拖慢恢复。
复制延迟会带来三种用户可见异常:
- 读己之写:用户写完后马上读,却从滞后副本看到旧值。
- 单调读:用户先看到新数据,后来请求落到旧副本,又看到旧数据,仿佛时间倒退。
- 一致前缀读:多个分区复制速度不同,用户可能先看到回答,再看到问题。
这些不是抽象理论,而是用户体验和业务正确性问题。解决方式包括从 leader 读、根据用户会话固定副本、基于时间戳或复制位置路由读请求、等待副本追上等。
多领导者复制允许多个 leader 接受写入,适合多数据中心、离线客户端、协同编辑等场景。但它引入写冲突。冲突可以避免,例如确保某个记录只由一个 leader 写;也可以解析,例如 last write wins、应用自定义合并、CRDT 等。LWW 能收敛,但会静默丢弃并发写,不适合不能丢数据的场景。
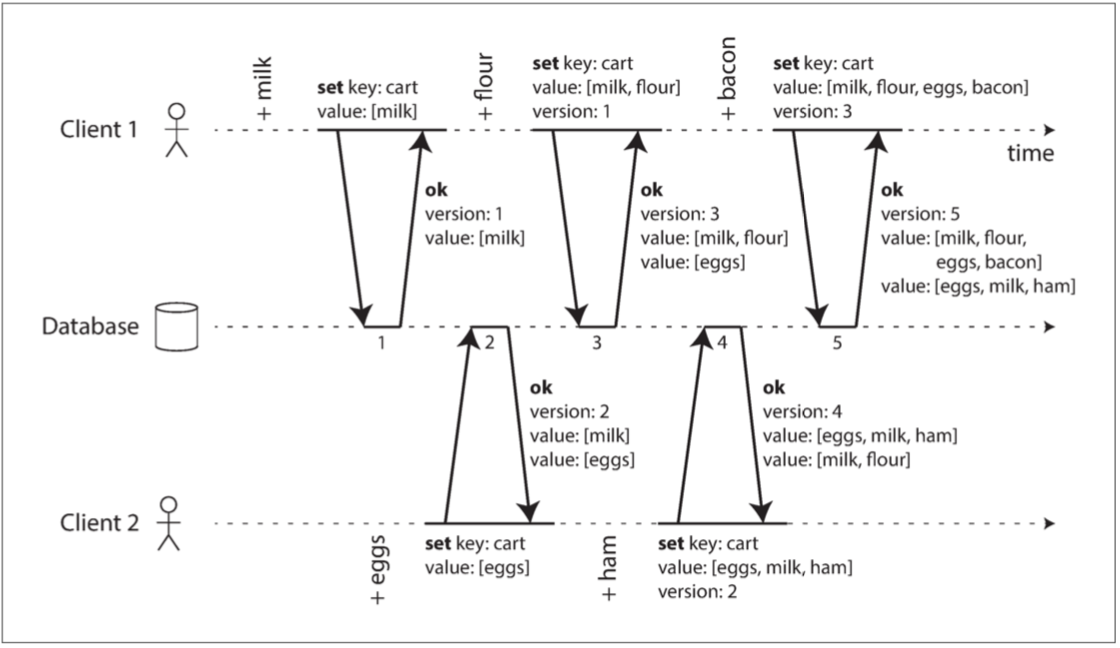
无领导者复制中,客户端向多个副本写,也从多个副本读。通常用 n、w、r 描述:n 个副本,写入要 w 个确认,读取要 r 个响应。如果 w + r > n,理论上读集合和写集合有交集,从而能看到最新写。但现实中还有并发写、故障恢复、sloppy quorum、hinted handoff、时钟问题和读取修复等复杂性。
本章最重要的思维是 happens-before。两个操作不是看物理时间是否重叠,而是看一方是否知道另一方。如果 B 基于 A 的结果写入,则 A happens before B;如果双方互不知道,则它们并发。版本向量记录因果依赖,用来区分覆盖和并发冲突。购物车例子说明:并发添加商品时不能简单丢弃某个值,客户端或系统必须合并 sibling,并用 tombstone 正确表达删除。
学习检查:
- 同步复制和异步复制在故障时差异是什么?
- 为什么 failover 可能导致数据丢失或 split brain?
- 读己之写、单调读、一致前缀读分别解决什么异常?
- LWW 为什么会牺牲 durability?
- happens-before 如何定义并发?
第 6 章:分区
复制解决副本问题,但如果数据太大或负载太高,单个节点即使有副本也扛不住。这时要分区,也叫 sharding。每条记录属于一个分区,分区分布在多个节点上。目标是让数据和查询负载均匀分散,避免热点。
按 key range 分区会把连续 key 范围放到同一分区。优点是范围查询高效,适合有序扫描。缺点是容易产生热点,例如以时间戳为 key 时,所有新写入集中到“今天”这个范围。解决办法可能是把传感器 ID 放在时间戳前面,让写入按传感器分散,但读取多个传感器的时间范围就要发多个查询。
按 key hash 分区会打散 key,使负载更均匀。缺点是破坏 key 的顺序,范围查询必须扫多个分区。Cassandra 的复合主键是一种折中:第一部分 hash 定位分区,后续列在分区内排序,从而支持“某用户某时间范围的更新”这类一对多查询。
热点无法完全靠 hash 解决。如果所有请求都打到同一个 celebrity key,hash 仍然会把同一个 key 路由到同一分区。应用可能需要手动拆热 key,例如给 key 加随机前缀,把写入拆到多个 key,再在读取时合并。这降低热点,但增加读取和维护成本。
二级索引遇到分区后更复杂。两种策略:
- 文档分区索引,也叫 local index。索引跟数据在同一分区。写入只更新一个分区,但按二级索引查询要 scatter/gather 到所有分区。
- 词项分区索引,也叫 global index。索引按被索引的值分区。读取能直接定位索引分区,但写入可能要更新多个索引分区,且异步维护时可能短暂不一致。
重平衡是节点增减时重新分配分区。不要用 hash(key) mod N,因为 N 一变,大量 key 都要移动。常见策略是预先创建远多于节点数的固定分区,新节点加入时从旧节点“偷”一些分区;或动态分区,分区变大后拆分;或让分区数与节点数成比例。自动重平衡方便但危险,可能在节点短暂慢响应时触发大量数据迁移,放大故障。很多系统保留人工确认。
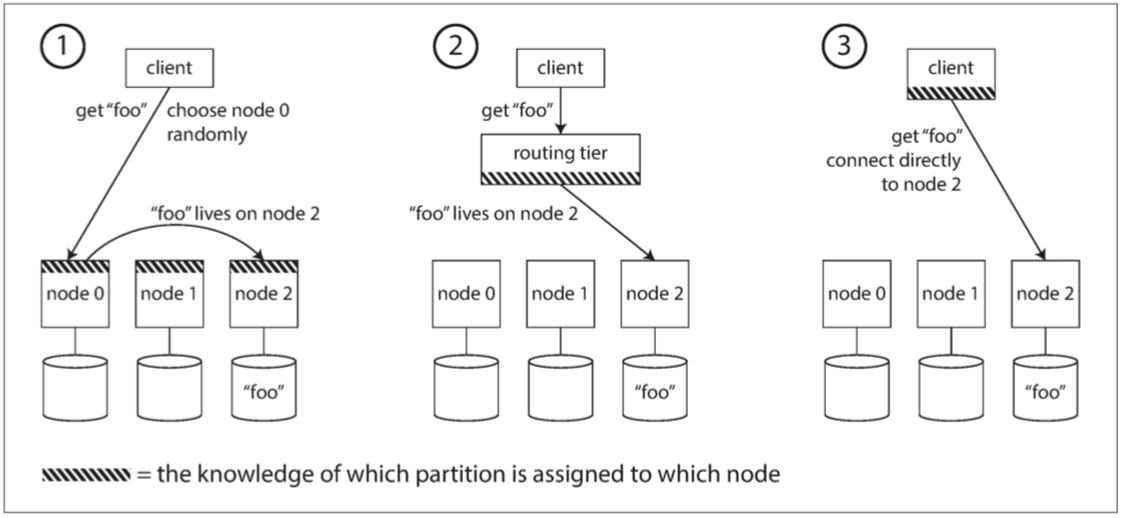
请求路由要解决:给定 key,客户端该连哪个节点?方案包括:请求发任意节点再转发;经过路由层;客户端自己知道分区映射。分区映射需要一致的元数据来源,很多系统用 ZooKeeper、配置服务器或 gossip 协议传播。
学习检查:
- key range 分区和 hash 分区各自牺牲了什么?
- 为什么 hash(key) mod N 不适合重平衡?
- local index 和 global index 的读写代价如何互换?
- 自动重平衡为什么可能放大故障?
第 7 章:事务
事务的作用是简化应用编程模型。它让应用可以把多个读写组合成一个逻辑单元:要么全部提交,要么全部回滚。没有事务,应用要自己处理进程崩溃、网络中断、磁盘满、部分写入成功、并发覆盖等错误组合。
ACID 常被当营销词使用,需要拆开理解:
- Atomicity 原子性:出错时能 abort,撤销本事务已经做的写入。这里不是并发意义的“不可分割”,更接近“可回滚性”。
- Consistency 一致性:数据库满足业务不变量。这个 C 很大程度是应用责任,数据库只能帮忙检查部分约束。
- Isolation 隔离性:并发事务互不干扰,理想情况是结果等价于串行执行。
- Durability 持久性:提交后数据不会轻易丢失,但绝对持久不存在,只能用磁盘、复制、备份降低风险。
弱隔离级别是本章重点。Read committed 防止脏读和脏写,但不防止 read skew。Snapshot isolation 给事务一个一致快照,通常用 MVCC 实现,可以防止 read skew,并让读写互不阻塞。但 snapshot isolation 仍可能出现 lost update、write skew 和某些 phantom 问题。
医生值班例子是 write skew 的经典说明:规则要求至少一名医生值班。两个医生同时读取到“还有两人值班”,各自把自己设为不值班。每个事务单独看都没问题,但最终没人值班,违反业务不变量。Snapshot isolation 无法阻止这种异常,因为两个事务写的是不同记录。只有 serializable isolation 能从根上防止。
Serializable 是最强隔离级别,让并发事务结果等价于某个串行顺序。实现方式有三种:
- 真正串行执行:简单可靠,但吞吐受单线程或单分区限制。适合每个事务很短、数据能按分区独立处理的场景。
- Two-phase locking,2PL:读写加锁,先获取锁再释放锁,能实现串行化,但可能阻塞、死锁、尾延迟高。
- Serializable snapshot isolation,SSI:乐观并发控制。事务先在快照上执行,提交时检测是否基于过期前提做了决定,如果不安全则 abort。它保留 snapshot isolation 的读写不阻塞优势,但在高冲突下 abort 成本会上升。
事务不是越强越好,也不是天然不可扩展。正确问题是:你的业务不变量、并发模式和故障模式需要数据库帮你屏蔽哪些复杂性?如果访问模式只是单对象读写,可能不用多对象事务。如果有反范式计数、跨行约束、余额转账、唯一性检查、库存扣减,事务能显著减少应用需要手写的错误处理。
学习检查:
- ACID 中哪个 C 主要是应用责任?
- Snapshot isolation 为什么仍会出现 write skew?
- lost update 和 dirty write 有什么区别?
- 2PL 和 SSI 是悲观还是乐观?各自代价是什么?
第 8 章:分布式系统的麻烦
单机程序通常给人一种确定性幻觉:要么工作,要么崩溃。分布式系统不同,它的核心特征是部分失败。某些节点正常,某些节点宕机,某些网络链路变慢,某些请求已经处理但响应丢失,系统处在一种调用方无法完全知道真实状态的世界。
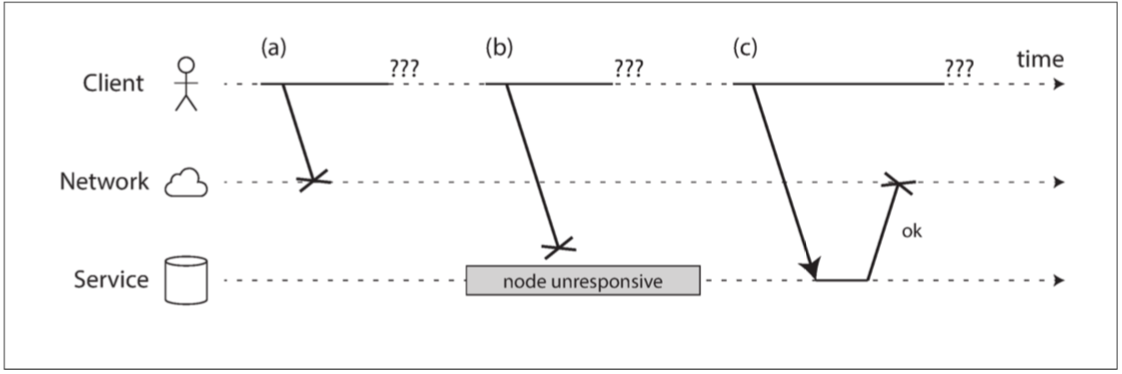
网络是不可靠的。你发出请求后没有收到响应,无法区分:请求丢了、对方宕机、请求排队、对方处理了但响应丢了、响应正在路上。timeout 只能说明你等不下去了,不能说明对方没处理。因此所有跨网络协议都必须面对“不知道是否成功”的状态。
故障检测也不可靠。系统通常用心跳和 timeout 判断节点是否死亡,但网络延迟、GC pause、CPU 饱和、交换机队列拥塞都会造成误判。某个节点可能不是死了,而是极慢。极慢节点比干净宕机更难处理。
时钟也不可靠。Time-of-day clock 可能跳变,受 NTP 调整影响;monotonic clock 适合测量持续时间,但不能比较不同机器上的绝对时间。依赖物理时间戳做写入顺序会出错,因为时钟可能不同步。即使使用同步时钟,也应把读数看成一个置信区间,而不是精确点。
进程暂停是另一个隐蔽问题。GC、虚拟机暂停、操作系统调度、磁盘 I/O、信号处理都可能让进程长时间停止。进程恢复后可能以为自己还持有锁或租约,但其他节点已经认为它死了并把资源交给别人。为防止这种旧持有者继续写坏数据,需要 fencing token:每次获取锁时给出递增 token,资源端只接受更大 token 的写入。
本章还区分了系统模型:
- 同步模型:网络延迟、进程暂停、时钟漂移都有已知上界。现实互联网服务通常不满足。
- 部分同步模型:大多数时候表现良好,但偶尔延迟和暂停可以任意大。现实中最有用。
- 异步模型:不允许依赖时间假设,甚至没有时钟。理论上更严格,但能做的事少。
节点故障模型包括 crash-stop、crash-recovery 和 Byzantine。大多数数据系统假设非拜占庭故障,也就是节点不会恶意撒谎。但工程上仍应防御弱形式的“撒谎”:校验和、输入校验、多 NTP 源等。
安全性和活性是理解分布式算法的两个关键词。安全性是“坏事永远不发生”,一旦违反就无法撤销;活性是“好事最终会发生”,可能暂时不满足但未来还有希望。分布式算法通常要求安全性在所有故障下都保持,而活性可以在网络最终恢复、多数节点可用等条件下成立。
学习检查:
- 为什么 timeout 不能证明远程节点已经死了?
- 为什么物理时钟不适合直接决定事件顺序?
- fencing token 解决了什么问题?
- 安全性和活性有什么区别?
第 9 章:一致性与共识
本章讨论分布式系统能提供哪些强保证,以及这些保证的代价。
最终一致性只说:如果停止写入并等足够久,副本最终会收敛。它没有说明多久收敛,也没有保证写后立刻读能看到新值。应用如果不理解这个弱保证,很容易在故障或高并发时出现隐蔽 bug。
线性一致性试图给应用一个错觉:虽然系统有多个副本,但看起来像只有一个副本,所有操作都在某个瞬间原子生效。它是新鲜度保证:一旦某个读已经看到新值,之后所有读都不能再看到旧值。它很容易理解,适合锁、leader election、唯一性约束、跨通道时序依赖等场景。
线性一致性的代价是协调。网络分区时,如果要保持线性一致性,少数派分区必须不可用;如果继续接受读写,就可能破坏单副本幻觉。这就是 CAP 讨论的核心。但原书提醒:CAP 过度简化,真实系统还要考虑延迟、复制方式、故障检测、读写路径等。更实用的问题是:你愿意为哪些操作支付线性一致性的代价?
因果一致性弱于线性一致性。它不要求所有操作排成单一全序,只要求有因果依赖的事件保持顺序;没有因果关系的事件可以并发。Lamport timestamp 能给事件一个与因果一致的全序,但它不能解决所有问题。例如用户名唯一性不能只靠时间戳,因为两个节点并发接受同名注册时,需要做一个唯一决定。
Total order broadcast 是把所有消息按同一顺序交付给所有节点。它和共识等价:如果能做 total order broadcast,就能实现线性一致存储;如果有线性一致 compare-and-set,也能实现 total order broadcast。
分布式事务的 atomic commit 也归约到共识。Two-phase commit 让协调者询问所有参与者是否准备提交;如果都 yes,再决定 commit。问题是协调者在参与者 yes 之后崩溃,参与者会处于 in-doubt 状态,不知道该提交还是回滚,只能阻塞等待协调者恢复。因此 2PC 不是容错共识算法。
容错共识算法如 Paxos、Raft、Viewstamped Replication 的价值在于:只要多数节点正常并能通信,就能在保持安全性的前提下继续做决定。共识能用于 leader election、成员管理、分区分配、锁、租约、配置管理等。但它不免费:需要多数派,节点数通常为 3 或 5;少数派不可用;网络抖动会导致 leader 频繁切换;动态成员变更复杂。
ZooKeeper、etcd 这类协调服务把共识能力外包出来。它们不适合作通用大数据量数据库,而适合存小规模、低频变化的协调元数据:谁是 leader,哪个节点负责哪个分区,某个锁是否被持有。它们提供线性一致原子操作、全序操作编号、会话、临时节点、变更通知,帮助应用构建可靠协调。
学习检查:
- 线性一致性和串行化有什么区别?
- 为什么唯一性约束通常需要共识?
- 2PC 为什么可能阻塞?
- ZooKeeper 为什么不适合作普通业务数据库?
第 10 章:批处理
前两部分主要讨论在线系统:请求进来,系统尽快返回响应。第 10 章转向离线系统:读取大量有界输入,运行一个 job,产生输出。批处理通常没有用户在等待,性能指标是吞吐,而不是单次响应时间。
Unix 工具链是批处理哲学的原型。日志分析可以用 cat | awk | sort | uniq | sort | head 完成。这里重要的不是命令本身,而是设计思想:
- 每个工具只做好一件事。
- 输出可以成为未知下游的输入。
- 统一接口是文件和管道。
- 逻辑和连接方式分离。
- 中间结果透明,便于实验和调试。
MapReduce 把类似思想扩展到分布式文件系统。mapper 读取输入块,产生 key-value;框架按 key 分区、排序、shuffle,把相同 key 的数据送到同一个 reducer。reducer 聚合或 join 后输出结果。输入不可变,输出只在任务成功后可见,所以失败任务可以重试,失败输出可以丢弃。这给了批处理非常强的容错语义:可见结果像没有故障一样。
MapReduce 中 join 是理解分布式算法的好例子:
- Reduce-side sort-merge join:两边输入都按 join key 发送到 reducer,同 key 汇合后 join。通用但 shuffle 成本高。
- Broadcast hash join:一边很小,复制到所有 mapper 内存中,大表流式扫描并查小表 hash。避免大表 shuffle。
- Partitioned hash join:两边已经按相同方式分区,可以每个分区本地 join。
批处理输出通常是派生数据:搜索索引、机器学习模型、推荐结果、报表、物化视图。输出最好整体替换或原子发布,避免下游看到半成品。批处理的函数应尽量无外部副作用,使重试安全。
MapReduce 的缺点是中间结果频繁落到 HDFS,故障恢复简单但性能差。Spark、Tez、Flink 等数据流引擎把计算表达成 DAG,减少不必要的落盘,在内存和网络中传递中间数据。它们在无故障情况下更快,但节点失败时可能需要重算更多中间状态。
图计算是批处理中特殊场景。PageRank、连通性、最短路径等算法需要反复沿边传播信息。MapReduce 每轮读写全量数据效率低,Pregel/BSP 模型让每个顶点维护状态,并在迭代轮次间传消息。它更适合大图,但如果图能放进单机内存,单机算法常常比分布式更快。
学习检查:
- 为什么批处理的输入有界性很重要?
- Unix 哲学如何影响 MapReduce?
- reduce-side join 和 broadcast hash join 分别适合什么场景?
- 为什么批处理容易提供强容错语义?
第 11 章:流处理
流处理是批处理在无界数据上的对应物。批处理读取固定大小输入,知道什么时候结束;流处理输入永不结束,只能持续处理事件。
事件是小的、不可变的、自包含对象,表示某个时间发生的事情。生产者产生事件,消费者处理事件,相关事件组织成 topic 或 stream。消息系统要回答两个基本问题:
- 生产者比消费者快时怎么办?丢弃、缓冲,还是反压?
- 节点崩溃或离线时消息会不会丢?
传统 AMQP/JMS 风格 broker 把消息投递给消费者,消费者 ack 后删除消息。它适合异步 RPC、任务队列、顺序不重要且不需要回放历史的场景。消费者崩溃未 ack 时,broker 重投消息;但在负载均衡和重投下,消息顺序可能被打乱。
日志型 broker 把 topic 分成 partition,消息追加到分区日志里。消费者按 offset 读取并记录进度,broker 保留消息一段时间或按空间保留,因此消费者可以回放历史。Kafka 是典型例子。日志型 broker 更像数据库复制日志和日志结构存储,很适合流处理和派生状态维护。
数据库和流之间有强关系。数据库的每次写入可以看作一条 changelog。Change Data Capture 捕获数据库变更并把它们发送给搜索索引、缓存、数据仓库等派生系统。Event sourcing 更进一步,把事件日志作为系统事实来源,当前状态由事件折叠出来。日志压缩让事件流保留每个 key 的最新值,从而可以重建表。
流处理用途包括:
- 复杂事件处理:识别事件模式。
- 流式分析:窗口聚合、指标、告警。
- 维护物化视图:持续更新搜索索引、缓存、时间线。
- 流式搜索:新事件匹配已注册查询。
- 消息传递和异步任务。
时间是流处理难点。事件时间是事件实际发生时间,处理时间是系统看到事件的时间。用处理时间开窗会引入处理速率变化造成的伪影。窗口可以是滚动窗口、跳跃窗口、滑动窗口、会话窗口。迟到事件会让“什么时候窗口完整”变难,这一点和专门讨论流处理的书有相同核心。
流 join 有三类:
- stream-stream join:两个事件流在时间窗口内匹配,例如搜索和点击。
- stream-table join:事件流与数据库变更日志维护的本地表 join,例如用户行为补充用户资料。
- table-table join:两个表的 changelog join,维护 join 结果的物化视图,例如 Twitter 时间线缓存。
join 的时间依赖很重要。税率、用户资料、关注关系都会随时间变化。历史事件应该 join 当时有效的状态,还是当前状态?如果多个流之间没有确定顺序,重跑同一输入可能得到不同结果。因此有时要保留版本 ID 或历史状态,类似数据仓库中的 slowly changing dimension。
流处理容错比批处理难,因为输出持续产生,不能等任务结束再统一发布。方案包括 microbatch、checkpoint、内部事务、幂等写。Exactly-once 更准确说是 effectively-once:任务可能重跑,但最终外部可见效果像只处理一次。外部副作用仍然困难,必须依赖原子提交、幂等操作或去重元数据。
学习检查:
- 日志型 broker 和传统消息队列的核心差异是什么?
- Change Data Capture 如何帮助系统集成?
- stream-table join 为什么需要维护本地状态?
- 为什么流处理 exactly-once 离不开幂等或事务?
第 12 章:数据系统的未来
最后一章把全书串起来。现实应用通常需要多个专用工具:OLTP 数据库、搜索索引、缓存、数据仓库、机器学习系统、推荐系统、消息队列。没有一个系统能高效满足所有访问模式,因此数据集成成为核心问题。
作者主张用“派生数据”理解系统集成。某些系统是 system of record,是事实来源;其他系统通过转换从它派生出来,例如索引、缓存、物化视图、统计模型。关键是要清楚输入和输出:数据先写到哪里?哪个系统从哪个系统派生?派生顺序如何保证?
直接同时写数据库和搜索索引容易不一致,因为两个系统可能以不同顺序处理并发写。更稳妥的做法是让写入先进入一个能决定顺序的系统,例如数据库日志或事件日志,再用 CDC 或事件流按相同顺序更新派生系统。这样搜索索引是数据库的派生结果,而不是另一个独立事实来源。
派生数据和分布式事务是两种保持一致的路线。分布式事务用锁和原子提交让多个系统同步完成;日志派生用事件顺序、确定性处理、重试和幂等维护结果。前者给出更强时序保证,但性能和故障隔离差;后者更松耦合、更健壮,但默认异步,不能自动保证读己之写。
批处理和流处理都是派生数据的工具。批处理适合重算、修复错误、迁移 schema、生成新视图;流处理适合持续维护低延迟派生状态。Lambda Architecture 曾经用批层保证正确、流层提供低延迟,但双写两套逻辑复杂。更理想的方向是统一批流:同一套处理逻辑既能处理历史全量,也能处理新事件。
“拆开数据库”是本章的重要思想。传统数据库内部已经包含很多组件:存储、索引、查询处理、物化视图、复制日志、事务、缓存。未来应用可能把这些组件拆开,用事件日志和数据流把专用系统组合起来。这不是降低一致性要求,而是把依赖关系显式化,让每个派生状态都能被重放、审计和修复。
正确性需要端到端思维。系统内部的 exactly-once 不足以保证业务操作 exactly-once。比如转账请求超时后客户端重试,如果没有 operation ID,就可能重复扣款。解决方式是让每个业务操作携带唯一 ID,服务端记录已处理 ID,重复请求返回同一结果。这种去重必须在业务端到端边界完成。
约束可以异步检查。唯一性约束通常需要共识,但很多业务约束不一定必须同步阻塞。系统可以先接受请求,随后异步检查,如果违反约束再补偿或道歉。这更接近现实世界业务流程,也更适合跨地域、高可用场景。但它要求业务能接受延迟发现问题,并有补偿机制。
作者还强调审计和验证。不要盲信系统承诺,要设计可核查的数据流:输入事件、派生状态、操作 ID、日志、校验规则都应支持事后验证。软件 bug、数据损坏、错误模型都会发生,系统应能发现和修复。
最后一部分讨论伦理。数据可以帮助改善服务、医疗、交通和科学研究,也可能造成歧视、操纵、监控和权力不对称。隐私不是“什么都不公开”,而是人有权决定向谁透露什么。工程师设计数据系统时,不只是优化指标,还在塑造社会中的信息权力结构。收集数据要考虑长期风险、误用、泄露、未来政权和用户尊严。
学习检查:
- 什么是 system of record?什么是 derived data?
- 为什么用日志派生搜索索引比双写更可靠?
- 批流统一想解决 Lambda Architecture 的什么问题?
- operation ID 为什么是端到端 exactly-once 的关键?
- 为什么数据系统设计还涉及伦理责任?
3. 核心概念表
| 概念 | 中文译名 | 核心含义 |
|---|---|---|
| Data-intensive application | 数据密集型应用 | 主要复杂度来自数据量、数据变化速度和数据复杂度的应用。 |
| Reliability | 可靠性 | 出现故障时仍尽量正确提供服务。 |
| Scalability | 可扩展性 | 负载增长时有合理方式维持性能。 |
| Maintainability | 可维护性 | 系统便于运维、理解和演化。 |
| Fault | 故障 | 某个组件偏离预期。 |
| Failure | 失效 | 系统整体不能提供所需服务。 |
| Data model | 数据模型 | 描述数据如何表示、关联和查询的抽象。 |
| Document model | 文档模型 | 以自包含文档表示数据,适合树状结构。 |
| Relational model | 关系模型 | 用关系、元组和声明式查询表示数据。 |
| Graph model | 图模型 | 用顶点和边表示复杂关系。 |
| Index | 索引 | 从主数据派生的加速查询结构。 |
| LSM-tree | 日志结构合并树 | 通过 memtable、SSTable、合并压缩实现高写吞吐。 |
| B-tree | B 树 | 页式有序索引,广泛用于关系数据库。 |
| OLTP | 在线事务处理 | 面向用户请求,小范围读写,高并发低延迟。 |
| OLAP | 在线分析处理 | 面向分析查询,大范围扫描,高吞吐。 |
| Encoding | 编码 | 把内存结构转成可存储或传输的字节。 |
| Backward compatibility | 向后兼容 | 新代码能读旧数据。 |
| Forward compatibility | 向前兼容 | 旧代码能读新数据或忽略新增字段。 |
| Replication | 复制 | 同一数据在多个节点上保留副本。 |
| Replication lag | 复制延迟 | follower 滞后 leader 或副本之间进度不同。 |
| Quorum | 法定人数 | 用多数读写交集提高一致性概率的机制。 |
| Partitioning | 分区 | 把数据集拆成多个子集分布到不同节点。 |
| Hot spot | 热点 | 某个分区或 key 负载异常集中。 |
| Transaction | 事务 | 把多个读写包装成一个可提交或回滚的逻辑单元。 |
| Isolation level | 隔离级别 | 数据库防止并发异常的强度。 |
| Snapshot isolation | 快照隔离 | 事务从一致快照读取,读写通常不互相阻塞。 |
| Serializability | 串行化 | 并发执行结果等价于某个串行顺序。 |
| Partial failure | 部分失败 | 分布式系统中部分组件故障、部分仍正常。 |
| Linearizability | 线性一致性 | 多副本看起来像一个原子单副本。 |
| Consensus | 共识 | 多节点在故障下对某个不可撤销决定达成一致。 |
| Total order broadcast | 全序广播 | 所有节点以同一顺序交付消息。 |
| Batch processing | 批处理 | 处理有界输入并产生派生输出。 |
| Stream processing | 流处理 | 持续处理无界事件流。 |
| Change Data Capture | 变更数据捕获 | 把数据库写入日志转成可消费事件流。 |
| Event sourcing | 事件溯源 | 把事件日志作为事实来源,当前状态由事件派生。 |
| Derived data | 派生数据 | 从事实来源通过转换生成的数据。 |
| Idempotence | 幂等性 | 操作执行多次与执行一次效果相同。 |
4. 方法、模型与框架汇总
4.1 选择数据模型
- 如果数据是局部树状对象,优先考虑文档模型。
- 如果关系多、join 多、查询灵活,优先考虑关系模型。
- 如果核心查询是多跳关系遍历,考虑图模型。
- 如果业务演化会让关系越来越多,不要过早把所有东西嵌进文档。
4.2 选择存储引擎
- 写多、key-value、可接受后台压缩:考虑 LSM-tree。
- 读多、范围查询多、成熟事务需求强:B-tree 常更稳妥。
- 大规模分析、少列多行扫描:列式存储更合适。
- 索引不是越多越好,每个索引都要付出写入成本。
4.3 设计复制策略
- 单 leader 简单,冲突少,但 failover 和复制延迟要处理。
- 多 leader 适合多数据中心和离线写,但冲突解析复杂。
- 无 leader 可用性强,但一致性弱,应用要理解 quorum、siblings、版本向量。
- 异步复制要明确:leader 故障时是否接受丢失已确认写入。
4.4 设计分区策略
- 先明确查询模式,再选 key。
- key range 支持范围查询,但可能热点。
- hash 分区分散负载,但牺牲范围查询。
- 热点 key 需要业务层拆分和合并。
- 二级索引要明确 local index 还是 global index。
4.5 判断事务需求
- 只做单对象读写,可以弱化事务。
- 有反范式计数、跨行约束、多对象一致性,事务价值很高。
- Snapshot isolation 不是 serializable,不能自动防止 write skew。
- 如果业务不变量关键,优先使用真正的 serializable 或显式锁/约束。
4.6 设计分布式协调
- 不要自己随手实现 leader election、锁、成员管理。
- 如果需要共识,使用成熟系统如 ZooKeeper、etcd 或数据库自带共识。
- 线性一致性只用在真正需要强新鲜度的操作上。
- 对租约和锁配合 fencing token,防止暂停节点复活后写坏数据。
4.7 构建派生数据系统
- 明确 system of record。
- 通过日志或 CDC 推导搜索索引、缓存、数据仓库、物化视图。
- 派生函数尽量确定性、幂等、可重放。
- 支持全量重算,方便 schema 迁移、bug 修复和新视图生成。
5. 关键结论
- 数据系统设计不是选择某个流行数据库,而是理解访问模式、故障模型、演化路径和正确性要求。
- 抽象能降低复杂性,但错误抽象会隐藏关键差异,例如把 RPC 当本地函数。
- 分布式系统最大难点不是机器多,而是部分失败、网络不确定、时钟不可靠和无法获得全局事实。
- 强一致性、事务、共识都不是免费午餐,但它们能显著简化应用正确性。
- 弱保证系统也能工作,但应用必须清楚自己承担了哪些复杂性。
- 批处理和流处理的共同点是生成派生数据;差异在输入有界与无界。
- 日志是贯穿全书的核心结构:复制日志、LSM 日志、CDC、事件溯源、分区日志、全序广播都依赖日志思想。
- 可靠数据系统不只要防机器故障,还要防软件 bug、人为错误、误用和未来演化。
- 端到端正确性不能只靠中间件承诺,业务操作 ID、幂等、审计和验证同样重要。
- 数据系统影响真实的人,隐私、歧视、监控和权力不对称也是工程责任的一部分。
6. 学习路径建议
第一次学习时,不建议按所有细节硬啃。可以分四轮:
第一轮:建立全局模型。
读第 1、2、3、5、7、8、9、11 章的本文精炼版,先掌握数据系统目标、模型、存储、复制、事务、分布式故障、一致性和流处理。
第二轮:补齐工程机制。
重点看第 4、6、10 章。理解编码兼容、分区与路由、批处理执行模型。
第三轮:串联日志与派生数据。
回看第 3、5、10、11、12 章,专门整理“日志”这条线:append-only log、WAL、replication log、CDC、partitioned log、event sourcing、total order broadcast。
第四轮:结合项目复盘。
拿一个真实系统问:
- system of record 是什么?
- 有哪些派生数据?
- 哪些路径是同步写?哪些是异步派生?
- 哪些读要求线性一致?哪些可以最终一致?
- 事务边界在哪里?
- 失败后怎么恢复?能否重放和审计?
7. 总复习题
- 数据密集型应用和计算密集型应用的核心差异是什么?
- 为什么平均响应时间不是好的性能指标?
- 文档数据库在哪些场景下比关系数据库更自然?什么时候会变糟?
- LSM-tree 和 B-tree 如何体现写优化与读优化的取舍?
- 为什么列式存储适合 OLAP,但不适合普通 OLTP 写入?
- 向前兼容为什么比向后兼容更难?
- RPC 为什么不能被当成本地函数调用?
- 异步复制 leader 故障时可能发生什么?
- 为什么版本向量能区分覆盖和并发冲突?
- key range 分区为什么容易产生时间热点?
- local secondary index 和 global secondary index 如何交换读写成本?
- Snapshot isolation 能防止哪些异常?不能防止哪些异常?
- write skew 为什么只有 serializable 才能彻底防止?
- 网络请求超时后,调用方到底知道什么、不知道什么?
- 为什么租约需要 fencing token?
- 线性一致性和串行化分别解决什么问题?
- 为什么 total order broadcast 和共识等价?
- 2PC 和 2PL 为什么名字相似但解决的问题不同?
- MapReduce 为什么能安全重试失败任务?
- 流处理为什么比批处理更难实现 exactly-once?
- CDC 和 event sourcing 有什么联系和区别?
- 派生数据系统如何替代一部分分布式事务需求?
- operation ID 如何实现端到端去重?
- 为什么数据系统设计需要考虑伦理和隐私?
8. 压缩说明
本文保留了原书的主要知识结构、核心概念、代表性例子和工程权衡,压缩了以下内容:
- 详细代码示例,仅保留其说明意义。
- 大量参考文献、脚注和历史细节。
- 多个相似系统实现的细节差异。
- 对图查询语言、编码格式、批处理框架、共识算法的长篇展开。
- 第 12 章中大量伦理论证细节,仅保留作者核心立场和工程含义。
如果要继续深入,建议回到原书重点重读这些章节:第 5 章复制、第 7 章事务、第 8 章分布式故障、第 9 章一致性与共识、第 11 章流处理、第 12 章派生数据系统。这几章是 DDIA 最能改变系统设计思维的部分。