单元测试原则、实践与模式(八)
译者声明:本译文仅作为学习的记录,不作为商业用途,如有侵权请告知我删除。
本文禁止转载!
请支持原书正版:https://www.manning.com/books/unit-testing
Chapter 8 Why integration test?
Integration tests play an important role in your test suite. It’s also crucial to balance the number of unit and integration tests. You will see shortly what that role is and how to maintain the balance, but first, let me give you a refresher on what differentiates an integration test from a unit test.
集成测试在你的测试套件中起着重要作用。平衡单元测试和集成测试的数量也很关键。你很快就会看到这个作用是什么以及如何保持平衡,但首先,让我给你复习一下集成测试与单元测试的区别。
8.1.1 The role of integration tests
As you may remember from chapter 2, a unit test is a test that meets the following three requirements: 你可能还记得第2章,单元测试是一个满足以下三个要求的测试:
- Verifies a single unit of behavior, 验证一个单一的行为单元
- Does it quickly, 快速完成
- And does it in isolation from other tests. 并与其他测试隔离开来。
A test that doesn’t meet at least one of these three requirements falls into the category of integration tests. An integration test then is any test that is not a unit test.
不符合这三个要求中的至少一个的测试属于集成测试的范畴。那么,集成测试就是任何不是单元测试的测试。
In practice, integration tests almost always verify how your system works in integration with out-of-process dependencies. In other words, these tests cover the code from the controllers quadrant (see chapter 7 for more details about code quadrants). The diagram in figure 8.1 shows the typical responsibilities of unit and integration tests. Unit tests cover the domain model, while integration tests check the code that glues that domain model with out-of-process dependencies.
在实践中,集成测试几乎总是验证你的系统如何与进程外的依赖关系集成工作。换句话说,这些测试涵盖了控制器象限的代码(关于代码象限的更多细节,见第7章)。图8.1中的图表显示了单元和集成测试的典型职责。单元测试涵盖了领域模型,而集成测试则检查将该领域模型与进程外的依赖关系粘合在一起的代码。
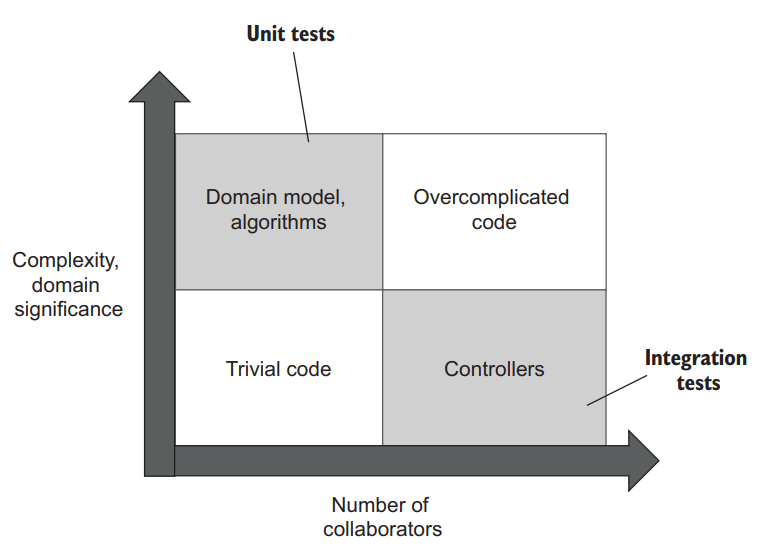
Figure 8.1 Integration tests cover controllers, while unit tests cover the domain model and algorithms. Trivial and overcomplicated code shouldn’t be tested at all. 图8.1 集成测试涵盖控制器,而单元测试涵盖领域模型和算法。琐碎和过于复杂的代码根本就不应该被测试。
Note that tests covering the controllers quadrant can sometimes be unit tests too. If all out-of-process dependencies are replaced with mocks, there will be no dependencies shared between tests, which will allow those tests to remain fast and maintain their isolation from each other. Most applications do have an out-of-process dependency that can’t be replaced with a mock, though. It’s usually a database—a dependency that is not visible to other applications.
注意,覆盖控制器象限的测试有时也可以是单元测试。如果所有进程外的依赖被替换成mocks,测试之间就不会有共享的依赖,这将使这些测试保持快速,并保持彼此的隔离。大多数应用程序确实有一个进程外的依赖,但不能用模拟来代替。它通常是一个数据库,一个对其他应用程序不可见的依赖。
As you may also remember from chapter 7, the other two quadrants from figure 8.1 (trivial code and overcomplicated code) shouldn’t be tested at all. Trivial code isn’t worth the effort, while overcomplicated code should be refactored into algorithms and controllers. Thus, all your tests must focus on the domain model and the controllers quadrants exclusively.
你可能还记得第七章,图8.1中的另外两个象限(琐碎的代码和过于复杂的代码)根本就不应该被测试。琐碎的代码不值得去做,而过于复杂的代码应该被重构为算法和控制器。因此,你的所有测试必须只关注领域模型和控制器的象限。
8.1.2 The Test Pyramid revisited
It’s important to maintain a balance between unit and integration tests. Working directly with out-of-process dependencies makes integration tests slow. Such tests are also more expensive to maintain. The increase in maintainability costs is due to 保持单元测试和集成测试之间的平衡是很重要的。直接与进程外的依赖关系一起工作会使集成测试变得缓慢。这种测试的维护成本也比较高。可维护性成本的增加是由于
- The necessity to keep the out-of-process dependencies operational 必须保持进程外的依赖关系的运行
- The greater number of collaborators involved, which inflates the test’s size 涉及到更多的合作者,这使得测试的规模扩大。
On the other hand, integration tests go through a larger amount of code (both your code and the code of the libraries used by the application), which makes them better than unit tests at protecting against regressions. They are also more detached from the production code and therefore have better resistance to refactoring.
另一方面,集成测试要通过大量的代码(包括你的代码和应用程序使用的库的代码),这使得它们比单元测试更能防止回归。它们也更多地从生产代码中分离出来,因此对重构有更好的抵抗力。
The ratio between unit and integration tests can differ depending on the project’s specifics, but the general rule of thumb is the following: check as many of the business scenario’s edge cases as possible with unit tests; use integration tests to cover one happy path, as well as any edge cases that can’t be covered by unit tests.
单元测试和集成测试之间的比例可以根据项目的具体情况而有所不同,但一般的经验法则是:用单元测试检查尽可能多的业务场景的边缘情况;用集成测试来覆盖一个happy path,以及任何单元测试不能覆盖的边缘情况。
DEFINITION
A happy path is a successful execution of a business scenario. An edge case is when the business scenario execution results in an error.
happy path是业务场景的成功执行。边缘案例是指业务场景的执行出现了错误。
Shifting the majority of the workload to unit tests helps keep maintenance costs low. At the same time, having one or two overarching integration tests per business scenario ensures the correctness of your system as a whole. This guideline forms the pyramid-like ratio between unit and integration tests, as shown in figure 8.2 (as discussed in chapter 2, end-to-end tests are a subset of integration tests).
将大部分工作负载转移到单元测试有助于保持低维护成本。同时,每个业务场景有一到两个总体的集成测试,可以确保你的系统整体上的正确性。这一准则在单元测试和集成测试之间形成了金字塔式的比例,如图8.2所示(正如第二章所讨论的,端到端测试是集成测试的一个子集)。
The Test Pyramid can take different shapes depending on the project’s complexity. Simple applications have little (if any) code in the domain model and algorithms quadrant. As a result, tests form a rectangle instead of a pyramid, with an equal number of unit and integration tests (figure 8.3). In the most trivial cases, you might have no unit tests whatsoever.
测试金字塔可以根据项目的复杂性采取不同的形状。简单的应用程序在领域模型和算法象限中的代码很少(如果有的话)。因此,测试形成一个矩形,而不是一个金字塔,单元和集成测试的数量相等(图8.3)。在最微不足道的情况下,你可能没有单元测试。
Note that integration tests retain their value even in simple applications. Regardless of how simple your code is, it’s still important to verify how it works in integration with other subsystems.
请注意,即使在简单的应用程序中,集成测试也保留其价值。不管你的代码有多简单,验证它在与其他子系统的集成中如何工作仍然很重要。
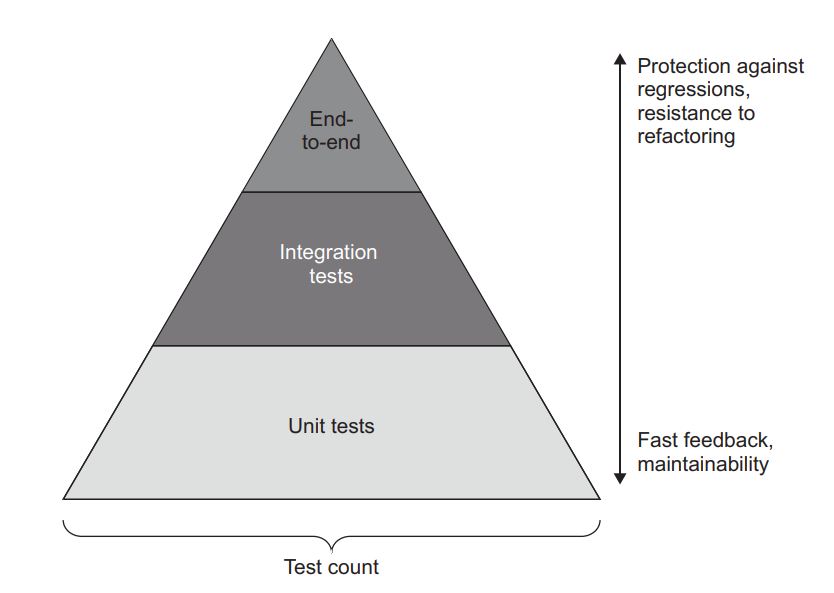
Figure 8.2 The Test Pyramid represents a trade-off that works best for most applications. Fast, cheap unit tests cover the majority of edge cases, while a smaller number of slow, more expensive integration tests ensure the correctness of the system as a whole. 图8.2 测试金字塔代表了一种对大多数应用来说最有效的权衡。快速、廉价的单元测试涵盖了大部分的边缘案例,而数量较少的缓慢、更昂贵的集成测试则确保了整个系统的正确性。

Figure 8.3 The Test Pyramid of a simple project. Little complexity requires a smaller number of unit tests compared to a normal pyramid. 图8.3 一个简单项目的测试金字塔。 与正常的金字塔相比,小的复杂性需要较少的单元测试。
8.1.3 Integration testing vs. failing fast
This section elaborates on the guideline of using integration tests to cover one happy path per business scenario and any edge cases that can’t be covered by unit tests.
本节阐述了使用集成测试来覆盖每个业务场景的一条happy path和任何单元测试无法覆盖的边缘情况的准则。
For an integration test, select the longest happy path in order to verify interactions with all out-of-process dependencies. If there’s no one path that goes through all such interactions, write additional integration tests—as many as needed to capture communications with every external system.
对于一个集成测试,选择最长的happy path,以验证与所有进程外依赖的交互。如果没有一条路径能通过所有这些交互,那就写额外的集成测试—根据需要来捕获与每个外部系统的通信。
As with the edge cases that can’t be covered by unit tests, there are exceptions to this part of the guideline, too. There’s no need to test an edge case if an incorrect execution of that edge case immediately fails the entire application. For example, you saw in chapter 7 how User from the sample CRM system implemented a CanChangeEmail method and made its successful execution a precondition for ChangeEmail(): 与单元测试不能覆盖的边缘情况一样,这部分准则也有例外。如果一个边缘案例的错误执行会立即导致整个应用程序的失败,那么就没有必要对该边缘案例进行测试。例如,你在第7章中看到,样本CRM系统中的User是如何实现CanChangeEmail方法的,并将其成功执行作为ChangeEmail()的前提条件:
public void ChangeEmail(string newEmail, Company company)
{
Precondition.Requires(CanChangeEmail() == null);
/* the rest of the method */
}The controller invokes CanChangeEmail() and interrupts the operation if that method returns an error: 控制器调用CanChangeEmail(),如果该方法返回一个错误,则中断操作:
// UserController
public string ChangeEmail(int userId, string newEmail)
{
object[] userData = _database.GetUserById(userId);
User user = UserFactory.Create(userData);
string error = user.CanChangeEmail();
if (error != null)
return error;
/* the rest of the method */
}This example shows the edge case you could theoretically cover with an integration test. Such a test doesn’t provide a significant enough value, though. If the controller tries to change the email without consulting with CanChangeEmail() first, the application crashes. This bug reveals itself with the first execution and thus is easy to notice and fix. It also doesn’t lead to data corruption.
这个例子显示了理论上你可以用一个集成测试来覆盖的边缘情况。不过这样的测试并没有提供足够重要的价值。如果控制器在没有咨询CanChangeEmail()的情况下试图改变电子邮件,应用程序会崩溃。这个错误在第一次执行时就暴露出来了,因此很容易被注意和修复。它也不会导致数据损坏。
TIP
It’s better to not write a test at all than to write a bad test. A test that doesn’t provide significant value is a bad test.
与其写一个糟糕的测试,不如不写一个测试。一个不能提供重要价值的测试是一个糟糕的测试。
Unlike the call from the controller to CanChangeEmail(), the presence of the precondition in User should be tested. But that is better done with a unit test; there’s no need for an integration test.
与控制器对CanChangeEmail()的调用不同,User中的前提条件的存在应该被测试。但这最好用单元测试来完成,没有必要用集成测试。
Making bugs manifest themselves quickly is called the Fail Fast principle, and it’s a viable alternative to integration testing.
让bug迅速表现出来被称为Fail Fast原则,它是集成测试的一个可行的替代方案。
The Fail Fast principle
The Fail Fast principle stands for stopping the current operation as soon as any unexpected error occurs. This principle makes your application more stable by 快速失败原则是指一旦发生任何意外的错误,立即停止当前的操作。这一原则通过以下方式使你的应用程序更加稳定
- Shortening the feedback loop—The sooner you detect a bug, the easier it is to fix. A bug that is already in production is orders of magnitude more expensive to fix compared to a bug found during development. 缩短反馈回路—越早发现错误,越容易修复。与开发过程中发现的错误相比,一个已经在生产中的错误的修复成本要高得多。
- Protecting the persistence state—Bugs lead to corruption of the application’s state. Once that state penetrates into the database, it becomes much harder to fix. Failing fast helps you prevent the corruption from spreading. 保护持久化状态Bug会导致应用程序状态的损坏。一旦该状态渗透到数据库中,它就变得更难修复。快速失败可以帮助你防止腐败的蔓延。
Stopping the current operation is normally done by throwing exceptions, because exceptions have semantics that are perfectly suited for the Fail Fast principle: they interrupt the program flow and pop up to the highest level of the execution stack, where you can log them and shut down or restart the operation.
停止当前的操作通常是通过抛出异常来实现的,因为异常的语义完全适合快速失败原则:它们会中断程序流并弹出到执行堆栈的最高层,在那里你可以记录它们并关闭或重新启动操作。
Preconditions are one example of the Fail Fast principle in action. A failing precondition signifies an incorrect assumption made about the application state, which is always a bug. Another example is reading data from a configuration file. You can arrange the reading logic such that it will throw an exception if the data in the configuration file is incomplete or incorrect. You can also put this logic close to the application startup, so that the application doesn’t launch if there’s a problem with its configuration.
前提条件是Fail Fast原则发挥作用的一个例子。一个失败的前提条件标志着对应用程序状态的不正确假设,这总是一个错误。另一个例子是从配置文件中读取数据。你可以安排读取逻辑,如果配置文件中的数据不完整或不正确,它将抛出一个异常。你也可以把这个逻辑放在靠近应用启动的地方,这样,如果配置有问题,应用就不会启动。
8.2 Which out-of-process dependencies to test directly
As I mentioned earlier, integration tests verify how your system integrates with out-ofprocess dependencies. There are two ways to implement such verification: use the real out-of-process dependency, or replace that dependency with a mock. This section shows when to apply each of the two approaches.
正如我前面提到的,集成测试验证你的系统如何与进程外的依赖关系集成。有两种方法可以实现这样的验证:使用真实的进程外依赖,或者用模拟的方式替换该依赖。本节将说明何时应用这两种方法中的每一种。
8.2.1 The two types of out-of-process dependencies
All out-of-process dependencies fall into two categories: 所有进程外的依赖关系分为两类:
- Managed dependencies (out-of-process dependencies you have full control over)—These dependencies are only accessible through your application; interactions with them aren’t visible to the external world. A typical example is a database. External systems normally don’t access your database directly; they do that through the API your application provides. 管理的依赖(你可以完全控制的进程外依赖)—这些依赖只能通过你的应用程序访问;与它们的交互对外部世界不可见。一个典型的例子是数据库。外部系统通常不直接访问你的数据库;他们通过你的应用程序提供的API进行访问。
- Unmanaged dependencies (out-of-process dependencies you don’t have full control over)— Interactions with such dependencies are observable externally. Examples include an SMTP server and a message bus: both produce side effects visible to other applications. 非管理的依赖关系(你不能完全控制的进程外依赖关系)—与这种依赖关系的交互在外部是可以观察到的。例子包括SMTP服务器和消息总线:两者都会产生对其他应用程序可见的副作用。
I mentioned in chapter 5 that communications with managed dependencies are implementation details. Conversely, communications with unmanaged dependencies are part of your system’s observable behavior (figure 8.4). This distinction leads to the difference in treatment of out-of-process dependencies in integration tests.
我在第五章中提到,与受管理的依赖关系的通信是实现细节。相反,与非托管依赖关系的通信是系统可观察行为的一部分(图 8.4)。这种区别导致了在集成测试中对进程外依赖关系处理的不同。
IMPORTANT
Use real instances of managed dependencies; replace unmanaged dependencies with mocks.
使用被管理的依赖关系的真实实例;用模拟代替非管理的依赖关系。
As discussed in chapter 5, the requirement to preserve the communication pattern with unmanaged dependencies stems from the necessity to maintain backward compatibility with those dependencies. Mocks are perfect for this task. With mocks, you can ensure communication pattern permanence in light of any possible refactorings.
正如第5章所讨论的,保留与非托管依赖关系的通信模式的要求源于保持与这些依赖关系向后兼容的必要性。mock是这项任务的完美选择。有了模拟,你可以在任何可能的重构中确保通信模式的永久性。

Figure 8.4 Communications with managed dependencies are implementation details; use such dependencies as-is in integration tests. Communications with unmanaged dependencies are part of your system’s observable behavior. Such dependencies should be mocked out. 图 8.4 与被管理的依赖关系的通信是实现细节;在集成测试中按原样使用这种依赖关系。与非管理的依赖关系的通信是系统可观察行为的一部分。 这样的依赖关系应该被模拟出来。
However, there’s no need to maintain backward compatibility in communications with managed dependencies, because your application is the only one that talks to them. External clients don’t care how you organize your database; the only thing that matters is the final state of your system. Using real instances of managed dependencies in integration tests helps you verify that final state from the external client’s point of view. It also helps during database refactorings, such as renaming a column or even migrating from one database to another.
然而,没有必要在与管理的依赖关系的通信中保持向后兼容,因为你的应用程序是唯一与它们对话的。外部客户并不关心你如何组织你的数据库;唯一重要的是你系统的最终状态。在集成测试中使用受管依赖的真实实例有助于从外部客户的角度验证最终状态。在数据库重构过程中也有帮助,比如重命名一个列,甚至从一个数据库迁移到另一个。
8.2.2 Working with both managed and unmanaged dependencies
Sometimes you’ll encounter an out-of-process dependency that exhibits attributes of both managed and unmanaged dependencies. A good example is a database that other applications have access to.
有时你会遇到一个进程外的依赖关系,它同时表现出受管和非受管依赖关系的属性。一个很好的例子是其他应用程序可以访问的数据库。
The story usually goes like this. A system begins with its own dedicated database. After a while, another system begins to require data from the same database. And so the team decides to share access to a limited number of tables just for ease of integration with that other system. As a result, the database becomes a dependency that is both managed and unmanaged. It still contains parts that are visible to your application only; but, in addition to those parts, it also has a number of tables accessible by other applications
这个故事通常是这样的。一个系统开始有自己的专用数据库。一段时间后,另一个系统开始需要同一数据库的数据。于是,团队决定共享对有限数量的表的访问,只是为了方便与其他系统的整合。结果,数据库变成了一个既受管理又不受管理的依赖关系。它仍然包含只对你的应用程序可见的部分;但是,除了这些部分之外,它也有一些其他应用程序可以访问的表
The use of a database is a poor way to implement integration between systems because it couples these systems to each other and complicates their further development. Only resort to this approach when all other options are exhausted. A better way to do the integration is via an API (for synchronous communications) or a message bus (for asynchronous communications).
使用数据库是实现系统间集成的一种糟糕的方式,因为它使这些系统相互耦合,使它们的进一步发展变得复杂。只有在所有其他选择都用尽的情况下才会采用这种方法。一个更好的方式是通过API(用于同步通信)或消息总线(用于异步通信)来实现集成。
But what do you do when you already have a shared database and can’t do anything about it in the foreseeable future? In this case, treat tables that are visible to other applications as an unmanaged dependency. Such tables in effect act as a message bus, with their rows playing the role of messages. Use mocks to make sure the communication pattern with these tables remains unchanged. At the same time, treat the rest of your database as a managed dependency and verify its final state, not the interactions with it (figure 8.5).
但是,当你已经有了一个共享的数据库,并且在可预见的未来无法对其采取任何措施时,你该怎么办呢?在这种情况下,把对其他应用程序可见的表作为一个非管理的依赖关系。这样的表实际上就像一个消息总线,它们的行扮演着消息的角色。使用模拟来确保与这些表的通信模式保持不变。同时,将数据库的其他部分作为受管依赖,并验证其最终状态,而不是与它的交互(图8.5)。

Figure 8.5 Treat the part of the database that is visible to external applications as an unmanaged dependency. Replace it with mocks in integration tests. Treat the rest of the database as a managed dependency. Verify its final state, not interactions with it. 图 8.5 将数据库中对外部应用程序可见的部分视为非管理依赖。在集成测试中用模拟来代替它。将数据库的其余部分视为受管依赖。 验证它的最终状态,而不是与它的交互。
It’s important to differentiate these two parts of your database because, again, the shared tables are observable externally, and you need to be careful about how your application communicates with them. Don’t change the way your system interacts with those tables unless absolutely necessary! You never know how other applications will react to such a change.
区分数据库的这两部分是很重要的,因为,共享表是可以从外部观察到的,你需要小心你的应用程序如何与它们进行通信。除非绝对必要,否则不要改变你的系统与这些表的交互方式!你永远不知道其他应用程序会如何反应!你永远不知道其他应用程序对这样的改变会有什么反应。
8.2.3 What if you can’t use a real database in integration tests?
Sometimes, for reasons outside of your control, you just can’t use a real version of a managed dependency in integration tests. An example would be a legacy database that you can’t deploy to a test automation environment, not to mention a developer machine, because of some IT security policy, or because the cost of setting up and maintaining a test database instance is prohibitive.
有时,由于你无法控制的原因,你不能在集成测试中使用一个真实版本的托管依赖。一个例子是一个遗留的数据库,你不能部署到测试自动化环境,更不用说开发人员的机器了,因为一些IT安全政策,或者因为设置和维护测试数据库实例的成本过高。
What should you do in such a situation? Should you mock out the database anyway, despite it being a managed dependency? No, because mocking out a managed dependency compromises the integration tests’ resistance to refactoring. Furthermore, such tests no longer provide as good protection against regressions. And if the database is the only out-of-process dependency in your project, the resulting integration tests would deliver no additional protection compared to the existing set of unit tests (assuming these unit tests follow the guidelines from chapter 7).
在这种情况下,你应该怎么做?你是否应该模拟出数据库,尽管它是一个可管理的依赖关系?不,因为模拟出一个被管理的依赖关系会影响集成测试对重构的抵抗力。此外,这样的测试不再提供对回归的良好保护。如果数据库是项目中唯一的进程外依赖,那么与现有的单元测试相比,所产生的集成测试不会提供额外的保护(假设这些单元测试遵循第7章的指南)。
The only thing such integration tests would do, in addition to unit tests, is check what repository methods the controller calls. In other words, you wouldn’t really gain confidence about anything other than those three lines of code in your controller being correct, while still having to do a lot of plumbing.
除了单元测试外,这种集成测试唯一要做的就是检查控制器调用了哪些Repositories方法。换句话说,除了控制器中的三行代码是正确的之外,你不会真正获得任何信心,同时还必须做大量的管道工作。
If you can’t test the database as-is, don’t write integration tests at all, and instead, focus exclusively on unit testing of the domain model. Remember to always put all your tests under close scrutiny. Tests that don’t provide a high enough value should have no place in your test suite.
如果你不能按原样测试数据库,就不要写集成测试,而要专注于领域模型的单元测试。记住,一定要把所有的测试放在严格的审查之下。那些不能提供足够高价值的测试在你的测试套件中不应该有任何位置。
8.3 Integration testing: An example
Let’s get back to the sample CRM system from chapter 7 and see how it can be covered with integration tests. As you may recall, this system implements one feature: changing the user’s email. It retrieves the user and the company from the database, delegates the decision-making to the domain model, and then saves the results back to the database and puts a message on the bus if needed (figure 8.6).
让我们回到第七章的CRM系统样本,看看如何用集成测试来覆盖它。你可能记得,这个系统实现了一个功能:改变用户的电子邮件。它从数据库中检索用户和公司,将决策委托给领域模型,然后将结果保存回数据库,如果需要的话,在总线上放一条消息(图8.6)。

Figure 8.6 The use case of changing the user’s email. The controller orchestrates the work between the database, the message bus, and the domain model. 图8.6 更改用户的电子邮件的用例。控制器协调了数据库、消息总线和领域模型之间的工作。
The following listing shows how the controller currently looks. 下面的清单显示了控制器目前的样子。
Listing 8.1 The user controller
public class UserController
{
private readonly Database _database = new Database();
private readonly MessageBus _messageBus = new MessageBus();
public string ChangeEmail(int userId, string newEmail)
{
object[] userData = _database.GetUserById(userId);
User user = UserFactory.Create(userData);
string error = user.CanChangeEmail();
if (error != null)
return error;
object[] companyData = _database.GetCompany();
Company company = CompanyFactory.Create(companyData);
user.ChangeEmail(newEmail, company);
_database.SaveCompany(company);
_database.SaveUser(user);
foreach (EmailChangedEvent ev in user.EmailChangedEvents)
{
_messageBus.SendEmailChangedMessage(ev.UserId, ev.NewEmail);
}
return "OK";
}
}In the following section, I’ll first outline scenarios to verify using integration tests. Then I’ll show you how to work with the database and the message bus in tests.
在下面的章节中,我将首先概述使用集成测试来验证的场景。然后我将告诉你如何在测试中使用数据库和消息总线。
8.3.1 What scenarios to test?
As I mentioned earlier, the general guideline for integration testing is to cover the longest happy path and any edge cases that can’t be exercised by unit tests. The longest happy path is the one that goes through all out-of-process dependencies.
正如我前面提到的,集成测试的一般准则是覆盖最长的happy path和任何不能被单元测试锻炼的边缘情况。最长的happy path是指通过所有进程外的依赖关系的路径。
In the CRM project, the longest happy path is a change from a corporate to a noncorporate email. Such a change leads to the maximum number of side effects: 在CRM项目中,最长的happy path是将公司的电子邮件改为非公司的电子邮件。这样的改变会导致最大数量的副作用:
- In the database, both the user and the company are updated: the user changes its type (from corporate to non-corporate) and email, and the company changes its number of employees. 在数据库中,用户和公司都被更新了:用户改变了它的类型(从公司到非公司)和电子邮件,公司改变了它的员工数量。
- A message is sent to the message bus. 一条消息被发送到消息总线上。
As for the edge cases that aren’t tested by unit tests, there’s only one such edge case: the scenario where the email can’t be changed. There’s no need to test this scenario, though, because the application will fail fast if this check isn’t present in the controller. That leaves us with a single integration test: 至于没有经过单元测试的边缘案例,只有一个这样的边缘案例:电子邮件不能被改变的情况。不过,没有必要测试这种情况,因为如果控制器中没有这个检查,应用程序会很快失败。这就给我们留下了一个单一的集成测试:
public void Changing_email_from_corporate_to_non_corporate()8.3.2 Categorizing the database and the message bus
Before writing the integration test, you need to categorize the two out-of-process dependencies and decide which of them to test directly and which to replace with a mock. The application database is a managed dependency because no other system can access it. Therefore, you should use a real instance of it. The integration test will
在编写集成测试之前,你需要对这两个进程外的依赖关系进行分类,并决定哪些要直接测试,哪些要用模拟程序代替。应用程序数据库是一个受管理的依赖关系,因为没有其他系统可以访问它。因此,你应该使用它的一个真实实例。集成测试将
- Insert a user and a company into the database. 在数据库中插入一个用户和一个公司。
- Run the change of email scenario on that database. 在该数据库上运行改变电子邮件的方案。
- Verify the database state. 验证数据库的状态。
On the other hand, the message bus is an unmanaged dependency—its sole purpose is to enable communication with other systems. The integration test will mock out the message bus and verify the interactions between the controller and the mock afterward.
另一方面,消息总线是一个非管理的依赖-它的唯一目的是实现与其他系统的通信。集成测试将模拟出消息总线,并在之后验证控制器和模拟的交互。
8.3.3 What about end-to-end testing?
There will be no end-to-end tests in our sample project. An end-to-end test in a scenario with an API would be a test running against a deployed, fully functioning version of that API, which means no mocks for any of the out-of-process dependencies (figure 8.7). On the other hand, integration tests host the application within the same process and substitute unmanaged dependencies with mocks (figure 8.8).
在我们的示例项目中,将没有端到端的测试。在有API的情况下,端到端测试是针对该API的已部署的、完全运作的版本运行的测试,这意味着没有任何进程外依赖的模拟(图8.7)。另一方面,集成测试在同一进程中托管应用程序,并用模拟来替代未管理的依赖(图8.8)。

Figure 8.7 End-to-end tests emulate the external client and therefore test a deployed version of the application with all out-of-process dependencies included in the testing scope. End-to-end tests shouldn’t check managed dependencies (such as the database) directly, only indirectly through the application. 图 8.7 端到端测试模拟外部客户端,因此测试应用程序的部署版本,所有进程外的依赖都包含在测试范围内。端到端测试不应该直接检查管理的依赖关系(如数据库),只能通过应用程序间接检查。

Figure 8.8 Integration tests host the application within the same process. Unlike end-to-end tests, integration tests substitute unmanaged dependencies with mocks. The only out-of-process components for integration tests are managed dependencies. 图8.8 集成测试在同一过程中托管应用程序。与端到端测试不同的是,集成测试用模拟来代替非托管的依赖关系。集成测试的唯一进程外组件是受管理的依赖关系。
As I mentioned in chapter 2, whether to use end-to-end tests is a judgment call. For the most part, when you include managed dependencies in the integration testing scope and mock out only unmanaged dependencies, integration tests provide a level of protection that is close enough to that of end-to-end tests, so you can skip end-toend testing. However, you could still create one or two overarching end-to-end tests that would provide a sanity check for the project after deployment. Make such tests go through the longest happy path, too, to ensure that your application communicates with all out-of-process dependencies properly. To emulate the external client’s behavior, check the message bus directly, but verify the database’s state through the application itself.
正如我在第二章提到的,是否使用端到端测试是一个判断。在大多数情况下,当你在集成测试范围内包括托管的依赖关系,并且只模拟出非托管的依赖关系时,集成测试提供的保护水平足以接近端到端测试,所以你可以跳过端到端测试。然而,你仍然可以创建一个或两个总体的端到端测试,在部署后为项目提供一个理智的检查。让这样的测试也通过最长的happy path,以确保你的应用程序与所有进程外的依赖关系正常通信。为了模仿外部客户端的行为,直接检查消息总线,但通过应用程序本身验证数据库的状态。
8.3.4 Integration testing: The first try
Here’s the first version of the integration test. 这里是集成测试的第一个版本。
Listing 8.2 The integration test
[Fact]
public void Changing_email_from_corporate_to_non_corporate()
{
// Arrange
var db = new Database(ConnectionString); // Database repository
User user = CreateUser(
"user@mycorp.com", UserType.Employee, db); // Creates the user and company in the database
CreateCompany("mycorp.com", 1, db);
var messageBusMock = new Mock<IMessageBus>(); // Sets up a mock for the message bus
var sut = new UserController(db, messageBusMock.Object);
// Act
string result = sut.ChangeEmail(user.UserId, "new@gmail.com");
// Assert
Assert.Equal("OK", result);
object[] userData = db.GetUserById(user.UserId); // Asserts the user’s state
User userFromDb = UserFactory.Create(userData);
Assert.Equal("new@gmail.com", userFromDb.Email);
Assert.Equal(UserType.Customer, userFromDb.Type);
object[] companyData = db.GetCompany(); // Asserts the company’s state
Company companyFromDb = CompanyFactory
.Create(companyData);
Assert.Equal(0, companyFromDb.NumberOfEmployees);
messageBusMock.Verify( // Checks the interactions with the mock
x => x.SendEmailChangedMessage(
user.UserId, "new@gmail.com"),
Times.Once);
}TIP
Notice that in the arrange section, the test doesn’t insert the user and the company into the database on its own but instead calls the CreateUser and CreateCompany helper methods. These methods can be reused across multiple integration tests.
注意,在准备部分,测试并没有自己插入用户和公司到数据库中,而是调用CreateUser和CreateCompany的辅助方法。这些方法可以在多个集成测试中重复使用。
It’s important to check the state of the database independently of the data used as input parameters. To do that, the integration test queries the user and company data separately in the assert section, creates new userFromDb and companyFromDb instances, and only then asserts their state. This approach ensures that the test exercises both writes to and reads from the database and thus provides the maximum protection against regressions. The reading itself must be implemented using the same code the controller uses internally: in this example, using the Database, UserFactory, and CompanyFactory classes.
独立于作为输入参数的数据,检查数据库的状态是很重要的。为了做到这一点,集成测试在断言部分分别查询用户和公司数据,创建新的userFromDb和companyFromDb实例,然后才断言它们的状态。这种方法保证了测试对数据库的写入和读出,从而对回归提供了最大的保护。读取本身必须使用控制器内部使用的相同代码实现:在这个例子中,使用数据库、UserFactory和CompanyFactory类。
This integration test, while it gets the job done, can still benefit from some improvement. For instance, you could use helper methods in the assertion section, too, in order to reduce this section’s size. Also, messageBusMock doesn’t provide as good protection against regressions as it potentially could. We’ll talk about these improvements in the subsequent two chapters where we discuss mocking and database testing best practices.
这个集成测试,虽然完成了工作,但仍然可以从一些改进中受益。例如,你也可以在断言部分使用辅助方法,以减少这部分的大小。另外,messageBusMock并没有像它可能提供的那样对回归提供良好的保护。我们将在随后的两章讨论mock和数据库测试的最佳实践中谈论这些改进。
8.4 Using interfaces to abstract dependencies
One of the most misunderstood subjects in the sphere of unit testing is the use of interfaces. Developers often ascribe invalid reasons to why they introduce interfaces and, as a result, tend to overuse them. In this section, I’ll expand on those invalid reasons and show in what circumstances the use of interfaces is and isn’t preferable.
在单元测试领域,最容易被误解的话题之一是接口的使用。开发人员经常对他们引入接口的原因进行无效的解释,结果是倾向于过度使用它们。在这一节中,我将对这些无效的理由进行扩展,并说明在哪些情况下使用接口是可取的,哪些是不可取的。
8.4.1 Interfaces and loose coupling
Many developers introduce interfaces for out-of-process dependencies, such as the database or the message bus, even when these interfaces have only one implementation. This practice has become so widespread nowadays that hardly anyone questions it. You’ll often see class-interface pairs similar to the following: 许多开发者为进程外的依赖关系引入接口,比如数据库或消息总线,即使这些接口只有一个实现。这种做法现在已经很普遍了,几乎没有人质疑它。你会经常看到类似于以下的类-接口对:
public interface IMessageBus
public class MessageBus : IMessageBus
public interface IUserRepository
public class UserRepository : IUserRepositoryThe common reasoning behind the use of such interfaces is that they help to 使用这种接口的普遍理由是,它们有助于
- Abstract out-of-process dependencies, thus achieving loose coupling 抽象进程外的依赖关系,从而实现松散耦合
- Add new functionality without changing the existing code, thus adhering to the Open-Closed principle (OCP) 在不改变现有代码的情况下增加新功能,从而遵守开放-封闭原则(OCP)。
Both of these reasons are misconceptions. Interfaces with a single implementation are not abstractions and don’t provide loose coupling any more than concrete classes that implement those interfaces. Genuine abstractions are discovered, not invented. The discovery, by definition, takes place post factum, when the abstraction already exists but is not yet clearly defined in the code. Thus, for an interface to be a genuine abstraction, it must have at least two implementations
这两个理由都是误解。只有一个实现的接口并不是抽象,也不会比实现这些接口的具体类更能提供松散耦合。真正的抽象是被发现的,而不是被发明的。根据定义,这种发现是在事后进行的,即当抽象已经存在但还没有在代码中明确定义时。因此,要使一个接口成为真正的抽象,它必须至少有两个实现。
The second reason (the ability to add new functionality without changing the existing code) is a misconception because it violates a more foundational principle: YAGNI. YAGNI stands for “You aren’t gonna need it” and advocates against investing time in functionality that’s not needed right now. You shouldn’t develop this functionality, nor should you modify your existing code to account for the appearance of such functionality in the future. The two major reasons are as follows: 第二个理由(在不改变现有代码的情况下增加新功能的能力)是一个误解,因为它违反了一个更基本的原则:YAGNI。YAGNI是 “你不会需要它 “的意思,主张不要在现在不需要的功能上投入时间。你不应该开发这种功能,也不应该修改你现有的代码以考虑将来出现这种功能。主要原因有以下两点:
- Opportunity cost—If you spend time on a feature that business people don’t need at the moment, you steer that time away from features they do need right now. Moreover, when the business people finally come to require the developed functionality, their view on it will most likely have evolved, and you will still need to adjust the already-written code. Such activity is wasteful. It’s more beneficial to implement the functionality from scratch when the actual need for it emerges. 机会成本—如果你把时间花在业务人员目前不需要的功能上,你就把这些时间从他们现在确实需要的功能上引开。此外,当业务人员最终需要所开发的功能时,他们对该功能的看法很可能已经发生变化,而你仍然需要调整已经写好的代码。这样的活动是浪费的。当实际需要出现时,从头开始实现功能会更有利。
- The less code in the project, the better. Introducing code just in case without an immediate need unnecessarily increases your code base’s cost of ownership. It’s better to postpone introducing new functionality until as late a stage of your project as possible. 项目中的代码越少越好。在没有迫切需求的情况下引入代码,会不必要地增加你的代码库的拥有成本。最好是将新功能的引入推迟到项目的后期阶段。
TIP
Writing code is an expensive way to solve problems. The less code the solution requires and the simpler that code is, the better.
编写代码是解决问题的一种昂贵方式。解决方案需要的代码越少越好,代码越简单越好。
There are exceptional cases where YAGNI doesn’t apply, but these are few and far between. For those cases, see my article “OCP vs YAGNI,” at https://enterprisecraftsmanship.com/posts/ocp-vs-yagni.
在一些特殊情况下,YAGNI并不适用,但这种情况很少,也很难出现。关于这些情况,请看我的文章 “OCP与YAGNI”,网址是https://enterprisecraftsmanship.com/posts/ocp-vs-yagni。
8.4.2 Why use interfaces for out-of-process dependencies?
So, why use interfaces for out-of-process dependencies at all, assuming that each of those interfaces has only one implementation? The real reason is much more practical and down-to-earth. It’s to enable mocking—as simple as that. Without an interface, you can’t create a test double and thus can’t verify interactions between the system under test and the out-of-process dependency.
那么,假设每个接口只有一个实现,为什么还要用接口来处理进程外的依赖关系呢?真正的原因是更加实际和朴实的。它是为了实现mock,就这么简单。没有接口,你就无法创建一个测试替身,从而无法验证被测系统和进程外依赖关系之间的交互。
Therefore, don’t introduce interfaces for out-of-process dependencies unless you need to mock out those dependencies. You only mock out unmanaged dependencies, so the guideline can be boiled down to this: use interfaces for unmanaged dependencies only. Still inject managed dependencies into the controller explicitly, but use concrete classes for that.
因此,不要为进程外依赖引入接口,除非你需要对这些依赖进行模拟。你只需要模拟出未被管理的依赖关系,所以这个准则可以归结为:只对未被管理的依赖关系使用接口。仍然可以明确地将管理的依赖注入到控制器中,但要使用具体的类。
Note that genuine abstractions (abstractions that have more than one implementation) can be represented with interfaces regardless of whether you mock them out. Introducing an interface with a single implementation for reasons other than mocking is a violation of YAGNI, however
请注意,真正的抽象(有一个以上实现的抽象)可以用接口来表示,无论你是否模拟它们。然而,出于mock以外的原因,引入一个只有一个实现的接口是违反YAGNI的。
And you might have noticed in listing 8.2 that UserController now accepts both the message bus and the database explicitly via the constructor, but only the message bus has a corresponding interface. The database is a managed dependency and thus doesn’t require such an interface. Here’s the controller: 在列表8.2中,你可能已经注意到,UserController现在通过构造函数明确地接受了消息总线和数据库,但只有消息总线有一个相应的接口。数据库是一个可管理的依赖关系,因此不需要这样的接口。这里是控制器:
public class UserController
{
private readonly Database _database;
private readonly IMessageBus _messageBus;
public UserController(Database database, IMessageBus messageBus)
{
_database = database;
_messageBus = messageBus;
}
public string ChangeEmail(int userId, string newEmail)
{
/* the method uses _database and _messageBus */
}
}NOTE
You can mock out a dependency without resorting to an interface by making methods in that dependency virtual and using the class itself as a base for the mock. This approach is inferior to the one with interfaces, though. I explain more on this topic of interfaces versus base classes in chapter 11.
你可以在不使用接口的情况下模拟出一个依赖关系,方法是将该依赖关系中的方法变成虚拟的,并使用该类本身作为模拟的基础。这种方法比使用接口的方法要差一些。关于接口与基类的问题,我将在第11章中进一步解释。
8.4.3 Using interfaces for in-process dependencies
You sometimes see code bases where interfaces back not only out-of-process dependencies but in-process dependencies as well. For example: 有时你会看到代码库中的接口不仅支持进程外的依赖,也支持进程内的依赖。比如说:
public interface IUser
{
int UserId { get; set; }
string Email { get; }
string CanChangeEmail();
void ChangeEmail(string newEmail, Company company);
}
public class User : IUser
{
/* ... */
}Assuming that IUser has only one implementation (and such specific interfaces always have only one implementation), this is a huge red flag. Just like with out-of-process dependencies, the only reason to introduce an interface with a single implementation for a domain class is to enable mocking. But unlike out-of-process dependencies, you should never check interactions between domain classes, because doing so results in brittle tests: tests that couple to implementation details and thus fail on the metric of resisting to refactoring (see chapter 5 for more details about mocks and test fragility).
假设IUser只有一个实现(而这种特定的接口总是只有一个实现),这是一个巨大的红旗。就像进程外依赖关系一样,为域类引入一个只有一个实现的接口的唯一原因是为了实现mock。但与进程外依赖不同的是,你不应该检查域类之间的交互,因为这样做会导致脆性测试:测试与实现细节相耦合,从而在抵抗重构的指标上失败(关于mocks和测试脆弱性的更多细节,见第5章)。
8.5 Integration testing best practices
There are some general guidelines that can help you get the most out of your integration tests: 有一些一般的准则可以帮助你从你的集成测试中获得最大的收益:
- Making domain model boundaries explicit 使领域模型的边界明确
- Reducing the number of layers in the application 减少应用程序中的层数
- Eliminating circular dependencies 消除循环依赖关系
As usual, best practices that are beneficial for tests also tend to improve the health of your code base in general. 像往常一样,有利于测试的最佳实践也倾向于改善你的代码库的总体健康状况。
8.5.1 Making domain model boundaries explicit
Try to always have an explicit, well-known place for the domain model in your code base. The domain model is the collection of domain knowledge about the problem your project is meant to solve. Assigning the domain model an explicit boundary helps you better visualize and reason about that part of your code.
尽量在你的代码库中为领域模型设置一个明确的、众所周知的位置。领域模型是关于你的项目所要解决的问题的领域知识的集合。为领域模型指定一个明确的边界,可以帮助你更好地可视化和推理你的代码的这一部分。
This practice also helps with testing. As I mentioned earlier in this chapter, unit tests target the domain model and algorithms, while integration tests target controllers. The explicit boundary between domain classes and controllers makes it easier to tell the difference between unit and integration tests.
这种做法也有助于测试。正如我在本章前面提到的,单元测试针对领域模型和算法,而集成测试针对控制器。领域类和控制器之间的明确边界使得单元测试和集成测试之间的区别更容易分辨。
The boundary itself can take the form of a separate assembly or a namespace. The particulars aren’t that important as long as all of the domain logic is put under a single, distinct umbrella and not scattered across the code base. 边界本身可以采取单独的汇编或命名空间的形式。只要所有的领域逻辑被放在一个单独的、不同的保护伞下,而不是散落在代码库中,具体的细节就不那么重要。
8.5.2 Reducing the number of layers
Most programmers naturally gravitate toward abstracting and generalizing the code by introducing additional layers of indirection. In a typical enterprise-level application, you can easily observe several such layers (figure 8.9).
大多数程序员自然倾向于通过引入额外的间接层来抽象和概括代码。在一个典型的企业级应用中,你可以很容易地看到几个这样的层(图8.9)。

Figure 8.9 Various application concerns are often addressed by separate layers of indirection. A typical feature takes up a small portion of each layer. 图8.9 各种应用关注点通常由不同的间接层来解决。一个典型的功能占据了每个层的一小部分。
In extreme cases, an application gets so many abstraction layers that it becomes too hard to navigate the code base and understand the logic behind even the simplest operations. At some point, you just want to get to the specific solution of the problem at hand, not some generalization of that solution in a vacuum.
在极端的情况下,一个应用程序会有如此多的抽象层,以至于很难浏览代码库和理解最简单的操作背后的逻辑。在某些时候,你只想得到手头问题的具体解决方案,而不是在真空中对该解决方案的一些概括。
All problems in computer science can be solved by another layer of indirection, except for the problem of too many layers of indirection. —David J. Wheeler
计算机科学中的所有问题都可以通过另一个间接层来解决,除了间接层太多的问题。-大卫-J-惠勒
Layers of indirection negatively affect your ability to reason about the code. When every feature has a representation in each of those layers, you have to expend significant effort assembling all the pieces into a cohesive picture. This creates an additional mental burden that handicaps the entire development process.
多层的间接性对你推理代码的能力有负面影响。当每一个特征在每一个层中都有表现时,你必须花费大量的精力将所有的碎片组装成一个连贯的画面。这就造成了一个额外的心理负担,阻碍了整个开发过程。
An excessive number of abstractions doesn’t help unit or integration testing, either. Code bases with many layers of indirections tend not to have a clear boundary between controllers and the domain model (which, as you might remember from chapter 7, is a precondition for effective tests). There’s also a much stronger tendency to verify each layer separately. This tendency results in a lot of low-value integration tests, each of which exercises only the code from a specific layer and mocks out layers underneath. The end result is always the same: insufficient protection against regressions combined with low resistance to refactoring.
过多的抽象概念也无助于单元或集成测试。有许多层间接关系的代码库往往在控制器和领域模型之间没有明确的界限(正如你可能记得的第七章,这是有效测试的前提条件)。还有一种更强烈的趋势是单独验证每一层。这种倾向导致了很多低价值的集成测试,每一个测试都只对特定层的代码进行练习,而对下面的层进行模拟。最终的结果总是一样的:对回归的保护不足,对重构的抵抗力低。
Try to have as few layers of indirection as possible. In most backend systems, you can get away with just three: the domain model, application services layer (controllers), and infrastructure layer. The infrastructure layer typically consists of algorithms that don’t belong to the domain model, as well as code that enables access to out-ofprocess dependencies (figure 8.10).
尽量减少间接性的层数。在大多数后端系统中,你可以只用三个:领域模型、应用服务层(控制器)和基础设施层。基础设施层通常包括不属于领域模型的算法,以及能够访问进程外依赖关系的代码(图8.10)。

Figure 8.10 You can get away with just three layers: the domain layer (contains domain logic), application services layers (provides an entry point for the external client, and coordinates the work between domain classes and out-of-process dependencies), and infrastructure layer (works with out-of-process dependencies; database repositories, ORM mappings, and SMTP gateways reside in this layer). 图 8.10 你可以只用三个层:领域层(包含领域逻辑)、应用服务层(为外部客户提供一个入口,并协调领域类和进程外依赖关系之间的工作)和基础设施层(与进程外依赖关系一起工作;数据库Repositories、ORM映射和SMTP网关都位于这一层)。
8.5.3 Eliminating circular dependencies
Another practice that can drastically improve the maintainability of your code base and make testing easier is eliminating circular dependencies.
另一个可以极大地提高代码库的可维护性并使测试更容易的做法是消除循环依赖关系。
DEFINITION
A circular dependency (also known as cyclic dependency) is two or more classes that directly or indirectly depend on each other to function properly.
循环依赖(也称为循环依赖)是指两个或更多的类直接或间接地依赖对方来正常工作。
A typical example of a circular dependency is a callback: 循环依赖的一个典型例子是回调:
public class CheckOutService
{
public void CheckOut(int orderId)
{
var service = new ReportGenerationService();
service.GenerateReport(orderId, this);
/* other code */
}
}
public class ReportGenerationService
{
public void GenerateReport(
int orderId,
CheckOutService checkOutService)
{
/* calls checkOutService when generation is completed */
}
}Here, CheckOutService creates an instance of ReportGenerationService and passes itself to that instance as an argument. ReportGenerationService calls CheckOutService back to notify it about the result of the report generation.
在这里,CheckOutService创建了一个ReportGenerationService的实例,并将自己作为一个参数传递给该实例。ReportGenerationService回调CheckOutService以通知它报告生成的结果。
Just like an excessive number of abstraction layers, circular dependencies add tremendous cognitive load when you try to read and understand the code. The reason is that circular dependencies don’t give you a clear starting point from which you can begin exploring the solution. To understand just one class, you have to read and understand the whole graph of its siblings all at once. Even a small set of interdependent classes can quickly become too hard to grasp
就像过多的抽象层一样,当你试图阅读和理解代码时,循环依赖会增加巨大的认知负担。原因是,循环依赖没有给你一个明确的起点,你可以从这个起点开始探索解决方案。为了理解一个类,你必须一下子阅读和理解它的兄弟姐妹的整个图。即使是一小部分相互依赖的类也会很快变得难以掌握。
Circular dependencies also interfere with testing. You often have to resort to interfaces and mocking in order to split the class graph and isolate a single unit of behavior, which, again, is a no-go when it comes to testing the domain model (more on that in chapter 5).
循环的依赖关系也会干扰测试。你常常不得不求助于接口和mock,以便分割类图并隔离单一的行为单元,这在测试领域模型时也是不可行的(更多内容见第五章)。
Note that the use of interfaces only masks the problem of circular dependencies. If you introduce an interface for CheckOutService and make ReportGenerationService depend on that interface instead of the concrete class, you remove the circular dependency at compile time (figure 8.11), but the cycle still persists at runtime. Even though the compiler no longer regards this class composition as a circular reference, the cognitive load required to understand the code doesn’t become any smaller. If anything, it increases due to the additional interface.
注意,接口的使用只是掩盖了循环依赖的问题。如果你为CheckOutService引入一个接口,并使ReportGenerationService依赖于该接口而不是具体的类,那么你在编译时就消除了循环依赖(图8.11),但在运行时循环仍然存在。尽管编译器不再将这种类的组合视为循环引用,但理解代码所需的认知负荷并没有变小。如果有的话,由于额外的接口,它还会增加。

Figure 8.11 With an interface, you remove the circular dependency at compile time, but not at runtime. The cognitive load required to understand the code doesn’t become any smaller. 图8.11 有了接口,你就可以在编译时消除循环依赖,但在运行时不会。理解代码所需的认知负荷并没有变小。
A better approach to handle circular dependencies is to get rid of them. Refactor ReportGenerationService such that it depends on neither CheckOutService nor the ICheckOutService interface, and make ReportGenerationService return the result of its work as a plain value instead of calling CheckOutService: 处理循环依赖关系的更好方法是摆脱它们。重构ReportGenerationService,使其既不依赖于CheckOutService,也不依赖于ICheckOutService接口,并使ReportGenerationService将其工作结果作为一个普通值返回,而不是调用CheckOutService:
public class CheckOutService
{
public void CheckOut(int orderId)
{
var service = new ReportGenerationService();
Report report = service.GenerateReport(orderId);
/* other work */
}
}
public class ReportGenerationService
{
public Report GenerateReport(int orderId)
{
/* ... */
}
}It’s rarely possible to eliminate all circular dependencies in your code base. But even then, you can minimize the damage by making the remaining graphs of interdependent classes as small as possible.
在你的代码库中,很少有可能消除所有的循环依赖关系。但即使如此,你也可以通过使剩余的相互依赖的类的图尽可能的小来减少损失。
8.5.4 Using multiple act sections in a test
As you might remember from chapter 3, having more than one arrange, act, or assert section in a test is a code smell. It’s a sign that this test checks multiple units of behavior, which, in turn, hinders the test’s maintainability. For example, if you have two related use cases—say, user registration and user deletion—it might be tempting to check both of these use cases in a single integration test. Such a test could have the following structure: 你可能还记得第三章的内容,在一个测试中拥有一个以上的 arrange, act, 或 assert 部分是一种代码气味。这是一个标志,表明这个测试检查了多个行为单元,这反过来又阻碍了测试的可维护性。例如,如果你有两个相关的用例—比如,用户注册和用户删除—它可能是诱人的,在一个单一的集成测试中检查这两个用例。这样的测试可以有以下结构:
- Arrange—Prepare data with which to register a user. 准备数据,用于注册用户。
- Act—Call UserController.RegisterUser(). 调用UserController.RegisterUser()。
- Assert—Query the database to see if the registration is completed successfully. 查询数据库,看注册是否成功完成。
- Act—Call UserController.DeleteUser(). 调用UserController.DeleteUser()。
- Assert—Query the database to make sure the user is deleted. 查询数据库以确保用户被删除。
This approach is compelling because the user states naturally flow from one another, and the first act (registering a user) can simultaneously serve as an arrange phase for the subsequent act (user deletion). The problem is that such tests lose focus and can quickly become too bloated.
这种方法很有说服力,因为用户状态自然而然地从彼此之间流动,第一个行为(注册用户)可以同时作为后续行为(删除用户)的安排阶段。问题是,这样的测试会失去重点,并会很快变得过于臃肿。
It’s best to split the test by extracting each act into a test of its own. It may seem like unnecessary work (after all, why create two tests where one would suffice?), but this work pays off in the long run. Having each test focus on a single unit of behavior makes those tests easier to understand and modify when necessary.
最好的办法是通过将每个行为提取到一个独立的测试中来分割测试。这似乎是不必要的工作(毕竟,为什么要创建两个测试,而一个就足够了?),但从长远来看,这项工作是值得的。每个测试都集中在一个单一的行为单元上,使这些测试在必要时更容易理解和修改。
The exception to this guideline is tests working with out-of-process dependencies that are hard to bring to a desirable state. Let’s say for example that registering a user results in creating a bank account in an external banking system. The bank has provisioned a sandbox for your organization, and you want to use that sandbox in an endto-end test. The problem is that the sandbox is too slow, or maybe the bank limits the number of calls you can make to that sandbox. In such a scenario, it becomes beneficial to combine multiple acts into a single test and thus reduce the number of interactions with the problematic out-of-process dependency
这条准则的例外是与进程外的依赖关系一起工作的测试,这些依赖关系很难达到理想的状态。比方说,注册用户的结果是在外部银行系统中创建一个银行账户。银行为你的组织提供了一个沙盒,你想在端到端测试中使用这个沙盒。问题是,该沙盒太慢了,或者银行限制了你对该沙盒的调用数量。在这种情况下,将多个行为合并到一个测试中,从而减少与有问题的进程外依赖的交互次数,会变得很有好处
Hard-to-manage out-of-process dependencies are the only legitimate reason to write a test with more than one act section. This is why you should never have multiple acts in a unit test—unit tests don’t work with out-of-process dependencies. Even integration tests should rarely have several acts. In practice, multistep tests almost always belong to the category of end-to-end tests.
难以管理的进程外依赖是编写一个有多个行为部分的测试的唯一合法理由。这就是为什么你不应该在单元测试中有多个行为—单元测试不能与进程外的依赖关系一起工作。即使是集成测试也不应该有多个行为。在实践中,多步骤测试几乎总是属于端到端测试的范畴。
8.6 How to test logging functionality
Logging is a gray area, and it isn’t obvious what to do with it when it comes to testing.
记录是一个灰色地带,当涉及到测试时,该如何处理它并不明显。
This is a complex topic that I’ll split into the following questions:
这是一个复杂的话题,我将把它分成以下几个问题:
- Should you test logging at all? 你到底要不要测试日志?
- If so, how should you test it? 如果是的话,你应该如何测试?
- How much logging is enough? 多少日志才算足够?
- How do you pass around logger instances? 你如何传递记录器的实例?
We’ll use our sample CRM project as an example. 我们将使用我们的CRM项目样本作为例子。
8.6.1 Should you test logging?
Logging is a cross-cutting functionality, which you can require in any part of your code base. Here’s an example of logging in the User class.
日志是一个跨领域的功能,你可以在你的代码库的任何部分要求它。下面是一个在用户类中进行日志记录的例子。
public class User
{
public void ChangeEmail(string newEmail, Company company)
{
_logger.Info( // Start of the method
$"Changing email for user {UserId} to {newEmail}");
Precondition.Requires(CanChangeEmail() == null);
if (Email == newEmail)
return;
UserType newType = company.IsEmailCorporate(newEmail)
? UserType.Employee
: UserType.Customer;
if (Type != newType)
{
int delta = newType == UserType.Employee ? 1 : -1;
company.ChangeNumberOfEmployees(delta);
_logger.Info( // Changes the user type
$"User {UserId} changed type " +
$"from {Type} to {newType}");
}
Email = newEmail;
Type = newType;
EmailChangedEvents.Add(new EmailChangedEvent(UserId, newEmail));
_logger.Info( // End of the method
$"Email is changed for user {UserId}");
}
}The User class records in a log file each beginning and ending of the ChangeEmail method, as well as the change of the user type. Should you test this functionality?
用户类在日志文件中记录了ChangeEmail方法的每次开始和结束,以及用户类型的变化。你应该测试这个功能吗?
On the one hand, logging generates important information about the application’s behavior. But on the other hand, logging can be so ubiquitous that it’s not obvious whether this functionality is worth the additional, quite significant, testing effort. The answer to the question of whether you should test logging comes down to this: Is logging part of the application’s observable behavior, or is it an implementation detail?
一方面,日志产生了关于应用程序行为的重要信息。但另一方面,日志记录可能无处不在,以至于这个功能是否值得付出额外的、相当大的测试努力并不明显。对于是否应该测试日志的问题,答案可以归结为以下几点: 记录是应用程序可观察行为的一部分,还是一个实现细节?
In that sense, it isn’t different from any other functionality. Logging ultimately results in side effects in an out-of-process dependency such as a text file or a database. If these side effects are meant to be observed by your customer, the application’s clients, or anyone else other than the developers themselves, then logging is an observable behavior and thus must be tested. If the only audience is the developers, then it’s an implementation detail that can be freely modified without anyone noticing, in which case it shouldn’t be tested.
在这个意义上,它和其他功能没有什么不同。日志最终会在进程外的依赖中产生副作用,如文本文件或数据库。如果这些副作用是为了让你的客户、应用程序的客户或除开发人员自己之外的其他人观察到,那么日志就是一种可观察的行为,因此必须进行测试。如果唯一的听众是开发人员,那么它就是一个实现细节,可以在没有人注意的情况下自由修改,在这种情况下,它不应该被测试。
For example, if you write a logging library, then the logs this library produces are the most important (and the only) part of its observable behavior. Another example is when business people insist on logging key application workflows. In this case, logs also become a business requirement and thus have to be covered by tests. However, in the latter example, you might also have separate logging just for developers.
例如,如果你写了一个日志库,那么这个库产生的日志就是其可观察行为中最重要(也是唯一)的部分。另一个例子是当业务人员坚持要记录关键的应用工作流程时。在这种情况下,日志也成为一种业务需求,因此必须由测试来覆盖。然而,在后一个例子中,你可能也有单独的日志记录,只是为了开发人员。
Steve Freeman and Nat Pryce, in their book Growing Object-Oriented Software, Guided by Tests (Addison-Wesley Professional, 2009), call these two types of logging support logging and diagnostic logging:
Steve Freeman和Nat Pryce在他们的书《Growing Object-Oriented Software, Guided by Tests》(Addison-Wesley Professional,2009)中,将这两种类型的日志称为支持性日志和诊断性日志:
- Support logging produces messages that are intended to be tracked by support staff or system administrators. 支持性日志产生的信息是为了让支持人员或系统管理员跟踪的。
- Diagnostic logging helps developers understand what’s going on inside the application. 诊断性日志帮助开发者了解应用程序内部发生了什么。
8.6.2 How should you test logging?
Because logging involves out-of-process dependencies, when it comes to testing it, the same rules apply as with any other functionality that touches out-of-process dependencies. You need to use mocks to verify interactions between your application and the log storage.
因为日志涉及进程外的依赖关系,所以当涉及到测试时,与其他涉及进程外依赖关系的功能适用同样的规则。你需要使用mocks来验证你的应用程序和日志存储之间的交互。
INTRODUCING A WRAPPER ON TOP OF ILOGGER
But don’t just mock out the ILogger interface. Because support logging is a business requirement, reflect that requirement explicitly in your code base. Create a special DomainLogger class where you explicitly list all the support logging needed for the business; verify interactions with that class instead of the raw ILogger.
但不要只是模拟出ILogger的接口。因为支持日志是一个业务需求,所以在你的代码库中明确地反映这个需求。创建一个特殊的DomainLogger类,明确列出业务所需的所有支持日志;用该类而不是原始ILogger来验证交互。
For example, let’s say that business people require you to log all changes of the users’ types, but the logging at the beginning and the end of the method is there just for debugging purposes. The next listing shows the User class after introducing a DomainLogger class.
例如,假设业务人员要求你记录用户类型的所有变化,但方法开始和结束时的记录只是为了调试的目的。下一个列表显示了引入DomainLogger类后的User类。
Listing 8.4 Extracting support logging into the DomainLogger class
public void ChangeEmail(string newEmail, Company company)
{
_logger.Info( // Diagnostic logging
$"Changing email for user {UserId} to {newEmail}");
Precondition.Requires(CanChangeEmail() == null);
if (Email == newEmail)
return;
UserType newType = company.IsEmailCorporate(newEmail)
? UserType.Employee
: UserType.Customer;
if (Type != newType)
{
int delta = newType == UserType.Employee ? 1 : -1;
company.ChangeNumberOfEmployees(delta);
_domainLogger.UserTypeHasChanged( // Support logging
UserId, Type, newType);
}
Email = newEmail;
Type = newType;
EmailChangedEvents.Add(new EmailChangedEvent(UserId, newEmail));
_logger.Info( // Diagnostic logging
$"Email is changed for user {UserId}");
}The diagnostic logging still uses the old logger (which is of type ILogger), but the support logging now uses the new domainLogger instance of type IDomainLogger. The following listing shows the implementation of IDomainLogger.
诊断日志仍然使用旧的日志器(属于ILogger类型),但支持日志现在使用新的IDomainLogger类型的domainLogger实例。下面的列表显示了IDomainLogger的实现。
Listing 8.5 DomainLogger as a wrapper on top of ILogger
public class DomainLogger : IDomainLogger
{
private readonly ILogger _logger;
public DomainLogger(ILogger logger)
{
_logger = logger;
}
public void UserTypeHasChanged(
int userId, UserType oldType, UserType newType)
{
_logger.Info(
$"User {userId} changed type " +
$"from {oldType} to {newType}");
}
}
DomainLogger works on top of ILogger: it uses the domain language to declare specific log entries required by the business, thus making support logging easier to understand and maintain. In fact, this implementation is very similar to the concept of structured logging, which enables great flexibility when it comes to log file postprocessing and analysis.
DomainLogger工作在ILogger之上:它使用领域语言来声明业务所需的特定日志条目,从而使支持日志更容易理解和维护。事实上,这种实现方式与结构化日志的概念非常相似,当涉及到日志文件的后期处理和分析时,它可以实现极大的灵活性。
UNDERSTANDING STRUCTURED LOGGING
Structured logging is a logging technique where capturing log data is decoupled from the rendering of that data. Traditional logging works with simple text.
A call like 结构化日志是一种日志技术,在这种技术中,捕获日志数据与呈现这些数据是脱钩的。传统的日志记录是以简单的文本来工作的。一个调用,如
logger.Info("User Id is " + 12);
first forms a string and then writes that string to a log storage. The problem with this approach is that the resulting log files are hard to analyze due to the lack of structure. For example, it’s not easy to see how many messages of a particular type there are and how many of those relate to a specific user ID. You’d need to use (or even write your own) special tooling for that. 首先形成一个字符串,然后将该字符串写入日志存储。这种方法的问题是,由于缺乏结构,产生的日志文件很难分析。例如,不容易看到有多少特定类型的消息,以及其中有多少与特定的用户ID有关。你需要使用(甚至自己编写)特殊的工具来实现。
On the other hand, structured logging introduces structure to your log storage. The use of a structured logging library looks similar on the surface: 另一方面,结构化日志为你的日志存储引入了结构。结构化日志库的使用在表面上看起来很相似:
logger.Info("User Id is {UserId}", 12);
But its underlying behavior differs significantly. Behind the scenes, this method computes a hash of the message template (the message itself is stored in a lookup storage for space efficiency) and combines that hash with the input parameters to form a set of captured data. The next step is the rendering of that data. You can still have a flat log file, as with traditional logging, but that’s just one possible rendering. You could also configure the logging library to render the captured data as a JSON or a CSV file, where it would be easier to analyze (figure 8.12).
但是它的底层行为却有很大的不同。在幕后,这个方法计算了消息模板的哈希值(为了空间效率,消息本身被存储在一个查找存储中),并将该哈希值与输入参数相结合,形成一组捕获的数据。下一步是对这些数据进行渲染。你仍然可以有一个平面的日志文件,就像传统的日志记录一样,但这只是一种可能的呈现方式。你也可以配置日志库,将捕获的数据呈现为JSON或CSV文件,这样会更容易分析(图8.12)。

Figure 8.12 Structured logging decouples log data from renderings of that data. You can set up multiple renderings, such as a flat log file, JSON, or CSV file. 图8.12 结构化日志将日志数据与该数据的呈现解耦。你可以设置多种呈现方式,如平面日志文件、JSON或CSV文件。
DomainLogger in listing 8.5 isn’t a structured logger per se, but it operates in the same spirit. Look at this method once again: 列表8.5中的DomainLogger本身并不是一个结构化的日志记录器,但它的操作精神是一样的。再看一下这个方法:
public void UserTypeHasChanged(
int userId, UserType oldType, UserType newType)
{
_logger.Info(
$"User {userId} changed type " +
$"from {oldType} to {newType}");
}You can view UserTypeHasChanged() as the message template’s hash. Together with the userId, oldType, and newType parameters, that hash forms the log data. The method’s implementation renders the log data into a flat log file. And you can easily create additional renderings by also writing the log data into a JSON or a CSV file.
你可以把UserTypeHasChanged()看作是消息模板的哈希值。与userId、oldType和newType参数一起,这个哈希值构成了日志数据。该方法的实现将日志数据渲染成一个平面日志文件。你可以通过将日志数据写入JSON或CSV文件来轻松创建额外的渲染。
WRITING TESTS FOR SUPPORT AND DIAGNOSTIC LOGGING
As I mentioned earlier, DomainLogger represents an out-of-process dependency—the log storage. This poses a problem: User now interacts with that dependency and thus violates the separation between business logic and communication with out-of-process dependencies. The use of DomainLogger has transitioned User to the category of overcomplicated code, making it harder to test and maintain (refer to chapter 7 for more details about code categories).
正如我前面提到的,DomainLogger代表了一个进程外的依赖性—日志存储。这带来了一个问题:用户现在与该依赖关系进行交互,因此违反了业务逻辑和与进程外依赖关系的通信之间的分离。对DomainLogger的使用使User过渡到过度复杂的代码类别,使其更难测试和维护(关于代码类别的更多细节请参考第7章)。
This problem can be solved the same way we implemented the notification of external systems about changed user emails: with the help of domain events (again, see chapter 7 for details). You can introduce a separate domain event to track changes in the user type. The controller will then convert those changes into calls to DomainLogger, as shown in the following listing.
这个问题可以用我们实现通知外部系统更改用户邮件的方法来解决:借助于域事件(同样,详见第七章)。你可以引入一个单独的域事件来跟踪用户类型的变化。然后,控制器将把这些变化转换成对DomainLogger的调用,如下面的列表所示。
Listing 8.6 Replacing DomainLogger in User with a domain event
public void ChangeEmail(string newEmail, Company company)
{
_logger.Info(
$"Changing email for user {UserId} to {newEmail}");
Precondition.Requires(CanChangeEmail() == null);
if (Email == newEmail)
return;
UserType newType = company.IsEmailCorporate(newEmail)
? UserType.Employee
: UserType.Customer;
if (Type != newType)
{
int delta = newType == UserType.Employee ? 1 : -1;
company.ChangeNumberOfEmployees(delta);
AddDomainEvent( // Uses a domain event instead of DomainLogger
new UserTypeChangedEvent(
UserId, Type, newType));
}
Email = newEmail;
Type = newType;
AddDomainEvent(new EmailChangedEvent(UserId, newEmail));
_logger.Info($"Email is changed for user {UserId}");
}Notice that there are now two domain events: UserTypeChangedEvent and EmailChangedEvent. Both of them implement the same interface (IDomainEvent) and thus can be stored in the same collection.
注意,现在有两个领域的事件: UserTypeChangedEvent和EmailChangedEvent。它们都实现了相同的接口(IDomainEvent),因此可以被存储在同一个集合中。
And here is how the controller looks.
下面是控制器的样子。
Listing 8.7 Latest version of UserController
public string ChangeEmail(int userId, string newEmail)
{
object[] userData = _database.GetUserById(userId);
User user = UserFactory.Create(userData);
string error = user.CanChangeEmail();
if (error != null)
return error;
object[] companyData = _database.GetCompany();
Company company = CompanyFactory.Create(companyData);
user.ChangeEmail(newEmail, company);
_database.SaveCompany(company);
_database.SaveUser(user);
_eventDispatcher.Dispatch(user.DomainEvents); // Dispatches user domain events
return "OK";
}EventDispatcher is a new class that converts domain events into calls to out-of-process dependencies:
EventDispatcher是一个新的类,它将领域事件转换为对进程外依赖关系的调用:
- EmailChangedEvent translates into _messageBus.SendEmailChangedMessage(). EmailChangedEvent转换为_messageBus.SendEmailChangedMessage()。
- UserTypeChangedEvent translates into _domainLogger.UserTypeHasChanged(). UserTypeChangedEvent转换为_domainLogger.UserTypeHasChanged()。
The use of UserTypeChangedEvent has restored the separation between the two responsibilities: domain logic and communication with out-of-process dependencies. Testing support logging now isn’t any different from testing the other unmanaged dependency, the message bus:
UserTypeChangedEvent的使用恢复了两个职责之间的分离:领域逻辑和与进程外依赖的通信。现在测试支持日志与测试其他非管理的依赖关系,即消息总线没有任何区别:
- Unit tests should check an instance of UserTypeChangedEvent in the User under test. 单元测试应该在被测用户中检查UserTypeChangedEvent的一个实例。
- The single integration test should use a mock to ensure the interaction with DomainLogger is in place. 单一的集成测试应该使用一个模拟来确保与DomainLogger的交互是到位的。
Note that if you need to do support logging in the controller and not one of the domain classes, there’s no need to use domain events. As you may remember from chapter 7, controllers orchestrate the collaboration between the domain model and out-of-process dependencies. DomainLogger is one of such dependencies, and thus UserController can use that logger directly.
注意,如果你需要在控制器中做支持日志,而不是在域类中做支持日志,那么就没有必要使用域事件。你可能还记得第七章,控制器协调了域模型和进程外的依赖关系之间的协作。DomainLogger就是这种依赖关系之一,因此UserController可以直接使用该记录器。
Also notice that I didn’t change the way the User class does diagnostic logging. User still uses the logger instance directly in the beginning and at the end of its ChangeEmail method. This is by design. Diagnostic logging is for developers only; you don’t need to unit test this functionality and thus don’t have to keep it out of the domain model.
另外注意到,我没有改变User类做诊断性日志的方式。User仍然在其ChangeEmail方法的开头和结尾处直接使用日志器实例。这是在设计上。诊断性日志仅适用于开发人员;你不需要对这个功能进行单元测试,因此不必把它放在领域模型之外。
Still, refrain from the use of diagnostic logging in User or other domain classes when possible. I explain why in the next section.
尽管如此,在可能的情况下,不要在用户或其他领域类中使用诊断性日志。我将在下一节中解释原因。
8.6.3 How much logging is enough?
Another important question is about the optimum amount of logging. How much logging is enough? Support logging is out of the question here because it’s a business requirement. You do have control over diagnostic logging, though.
另一个重要问题是关于日志的最佳数量。多少日志记录才够?支持性日志在这里是不可能的,因为它是一个商业要求。不过,你可以控制诊断性日志。
It’s important not to overuse diagnostic logging, for the following two reasons: 重要的是,不要过度使用诊断性日志,原因有二:
- Excessive logging clutters the code. This is especially true for the domain model. That’s why I don’t recommend using diagnostic logging in User even though such a use is fine from a unit testing perspective: it obscures the code. 过度的日志记录会使代码混乱。这对领域模型来说尤其如此。这就是为什么我不建议在User中使用诊断性日志,即使从单元测试的角度来看,这样的使用没有问题:它掩盖了代码。
- Logs’ signal-to-noise ratio is key. The more you log, the harder it is to find relevant information. Maximize the signal; minimize the noise. 日志的信噪比是关键。你的日志越多,就越难找到相关信息。使信号最大化;使噪音最小化。
Try not to use diagnostic logging in the domain model at all. In most cases, you can safely move that logging from domain classes to controllers. And even then, resort to diagnostic logging only temporarily when you need to debug something. Remove it once you finish debugging. Ideally, you should use diagnostic logging for unhandled exceptions only.
尽量不要在领域模型中使用诊断性日志。在大多数情况下,你可以安全地将日志记录从域类转移到控制器。即使如此,也只能在你需要调试的时候暂时使用诊断性日志。一旦你完成了调试,就删除它。理想情况下,你应该只对未处理的异常使用诊断性日志。
8.6.4 How do you pass around logger instances?
Finally, the last question is how to pass logger instances in the code. One way to resolve these instances is using static methods, as shown in the following listing.
最后,最后一个问题是如何在代码中传递记录器实例。解决这些实例的一种方法是使用静态方法,如下面清单所示。
Listing 8.8 Storing ILogger in a static field
public class User
{
private static readonly ILogger _logger =
LogManager.GetLogger(typeof(User)); //Resolves ILogger through a static method, and stores it in a private static field 通过静态方法解析 ILogger,并将其存储在私有静态字段中
public void ChangeEmail(string newEmail, Company company)
{
_logger.Info(
$"Changing email for user {UserId} to {newEmail}");
/* ... */
_logger.Info($"Email is changed for user {UserId}");
}
}Steven van Deursen and Mark Seeman, in their book Dependency Injection Principles, Practices, Patterns (Manning Publications, 2018), call this type of dependency acquisition ambient context. This is an anti-pattern. Two of their arguments are that
Steven van Deursen和Mark Seeman在他们的《依赖注入原则、实践、模式》(Manning Publications,2018)一书中,将这种类型的依赖获取称为环境背景。这是一种反模式。他们的两个论点是
- The dependency is hidden and hard to change. 依赖关系是隐藏的,很难改变。
- Testing becomes more difficult. 测试变得更加困难。
I fully agree with this analysis. To me, though, the main drawback of ambient context is that it masks potential problems in code. If injecting a logger explicitly into domain class becomes so inconvenient that you have to resort to ambient context, that’s a certain sign of trouble. You either log too much or use too many layers of indirection. In any case, ambient context is not a solution. Instead, tackle the root cause of the problem.
我完全同意这种分析。不过,对我来说,环境上下文的主要缺点是它掩盖了代码中的潜在问题。如果将日志记录器显式地注入到域类中变得如此不便,以至于你不得不求助于环境上下文,那么这无疑是一个麻烦的信号。你要么记录了太多的东西,要么使用了太多的暗示层。在任何情况下,环境上下文都不是一个解决方案。相反,要解决问题的根本原因。
The following listing shows one way to explicitly inject the logger: as a method argument. Another way is through the class constructor.
下面的列表显示了显式注入记录器的一种方法:作为方法参数。另一种方法是通过类的构造函数。
Listing 8.9 Injecting the logger explicitly
public void ChangeEmail(
string newEmail,
Company company,
ILogger logger)
{
logger.Info(
$"Changing email for user {UserId} to {newEmail}");
/* ... */
logger.Info($"Email is changed for user {UserId}");
}8.7 Conclusion
View communications with all out-of-process dependencies through the lens of whether this communication is part of the application’s observable behavior or an implementation detail. The log storage isn’t any different in that regard. Mock logging functionality if the logs are observable by non-programmers; don’t test it otherwise. In the next chapter, we’ll dive deeper into the topic of mocking and best practices related to it.
通过这种通信是应用程序可观察行为的一部分还是实现细节的角度来看待与所有进程外的依赖关系的通信。在这方面,日志存储并没有什么不同。如果日志可以被非程序员观察到,就模拟日志功能;否则就不要测试它。在下一章中,我们将深入探讨嘲弄的主题和与之相关的最佳实践。
Summary
-
An integration test is any test that is not a unit test. Integration tests verify how your system works in integration with out-of-process dependencies: – Integration tests cover controllers; unit tests cover algorithms and the domain model. – Integration tests provide better protection against regressions and resistance to refactoring; unit tests have better maintainability and feedback speed.
-
The bar for integration tests is higher than for unit tests: the score they have in the metrics of protection against regressions and resistance to refactoring must be higher than that of a unit test to offset the worse maintainability and feedback speed. The Test Pyramid represents this trade-off: the majority of tests should be fast and cheap unit tests, with a smaller number of slow and more expensive integration tests that check correctness of the system as a whole:
- – Check as many of the business scenario’s edge cases as possible with unit tests. Use integration tests to cover one happy path, as well as any edge cases that can’t be covered by unit tests.
- The shape of the Test Pyramid depends on the project’s complexity. Simple projects have little code in the domain model and thus can have an equal number of unit and integration tests. In the most trivial cases, there might be no unit tests.
-
The Fail Fast principle advocates for making bugs manifest themselves quickly and is a viable alternative to integration testing.
-
Managed dependencies are out-of-process dependencies that are only accessible through your application. Interactions with managed dependencies aren’t observable externally. A typical example is the application database.
-
Unmanaged dependencies are out-of-process dependencies that other applications have access to. Interactions with unmanaged dependencies are observable externally. Typical examples include an SMTP server and a message bus.
-
Communications with managed dependencies are implementation details; communications with unmanaged dependencies are part of your system’s observable behavior.
-
Use real instances of managed dependencies in integration tests; replace unmanaged dependencies with mocks.
-
Sometimes an out-of-process dependency exhibits attributes of both managed and unmanaged dependencies. A typical example is a database that other applications have access to. Treat the observable part of the dependency as an unmanaged dependency: replace that part with mocks in tests. Treat the rest of the dependency as a managed dependency: verify its final state, not interactions with it.
-
An integration test must go through all layers that work with a managed dependency. In an example with a database, this means checking the state of that database independently of the data used as input parameters.
-
Interfaces with a single implementation are not abstractions and don’t provide loose coupling any more than the concrete classes that implement those interfaces. Trying to anticipate future implementations for such interfaces violates the YAGNI (you aren’t gonna need it) principle.
-
The only legitimate reason to use interfaces with a single implementation is to enable mocking. Use such interfaces only for unmanaged dependencies. Use concrete classes for managed dependencies.
-
Interfaces with a single implementation used for in-process dependencies are a red flag. Such interfaces hint at using mocks to check interactions between domain classes, which leads to coupling tests to the code’s implementation details.
-
Have an explicit and well-known place for the domain model in your code base. The explicit boundary between domain classes and controllers makes it easier to tell unit and integration tests apart.
-
An excessive number of layers of indirection negatively affects your ability to reason about the code. Have as few layers of indirections as possible. In most backend systems, you can get away with just three of them: the domain model, an application services layer (controllers), and an infrastructure layer.
-
Circular dependencies add cognitive load when you try to understand the code. A typical example is a callback (when a callee notifies the caller about the result of its work). Break the cycle by introducing a value object; use that value object to return the result from the callee to the caller.
-
Multiple act sections in a test are only justified when that test works with out-ofprocess dependencies that are hard to bring into a desirable state. You should never have multiple acts in a unit test, because unit tests don’t work with out-ofprocess dependencies. Multistep tests almost always belong to the category of end-to-end tests.
-
Support logging is intended for support staff and system administrators; it’s part of the application’s observable behavior. Diagnostic logging helps developers understand what’s going on inside the application: it’s an implementation detail.
-
Because support logging is a business requirement, reflect that requirement explicitly in your code base. Introduce a special DomainLogger class where you list all the support logging needed for the business.
-
Treat support logging like any other functionality that works with an out-of-process dependency. Use domain events to track changes in the domain model; convert those domain events into calls to DomainLogger in controllers.
-
Don’t test diagnostic logging. Unlike support logging, you can do diagnostic logging directly in the domain model.
-
Use diagnostic logging sporadically. Excessive diagnostic logging clutters the code and damages the logs’ signal-to-noise ratio. Ideally, you should only use diagnostic logging for unhandled exceptions.
-
Always inject all dependencies explicitly (including loggers), either via the constructor or as a method argument.