单元测试原则、实践与模式(十)
译者声明:本译文仅作为学习的记录,不作为商业用途,如有侵权请告知我删除。
本文禁止转载!
请支持原书正版:https://www.manning.com/books/unit-testing
This chapter covers
- Prerequisites for testing the database 测试数据库的先决条件
- Database testing best practices 数据库测试的最佳实践
- Test data life cycle 测试数据的生命周期
- Managing database transactions in tests 在测试中管理数据库事务
The last piece of the puzzle in integration testing is managed out-of-process dependencies. The most common example of a managed dependency is an application database—a database no other application has access to.
集成测试中的最后一块拼图是管理进程外的依赖关系。管理的依赖关系最常见的例子是一个应用数据库—一个其他应用程序无法访问的数据库。
Running tests against a real database provides bulletproof protection against regressions, but those tests aren’t easy to set up. This chapter shows the preliminary steps you need to take before you can start testing your database: it covers keeping track of the database schema, explains the difference between the state-based and migration-based database delivery approaches, and demonstrates why you should choose the latter over the former.
针对一个真实的数据库运行测试,提供了对回归的防弹保护,但这些测试并不容易设置。本章展示了在开始测试数据库之前需要采取的初步步骤:包括跟踪数据库schema,解释基于状态的数据库交付方法和基于迁移的数据库交付方法之间的区别,并演示了为什么你应该选择后者而不是前者。
After learning the basics, you’ll see how to manage transactions during the test, clean up leftover data, and keep tests small by eliminating insignificant parts and amplifying the essentials. This chapter focuses on relational databases, but many the same principles are applicable to other types of data stores such as document-oriented databases or even plain text file storages.
在学习了基础知识之后,你将看到如何在测试过程中管理事务,清理遗留数据,并通过消除不重要的部分和放大精华部分来保持测试的小型化。本章的重点是关系型数据库,但许多相同的原则也适用于其他类型的数据存储,如面向文档的数据库甚至是纯文本文件存储。
10.1 Prerequisites for testing the database
测试数据库的先决条件
As you might recall from chapter 8, managed dependencies should be included as-is in integration tests. That makes working with those dependencies more laborious than unmanaged ones because using a mock is out of the question. But even before you start writing tests, you must take preparatory steps to enable integration testing. In this section, you’ll see these prerequisites:
正如你可能记得的那样,在第8章中,管理的依赖关系应该被原封不动地包含在集成测试中。这使得处理这些依赖关系比处理非管理的依赖关系更费劲,因为使用模拟是不可能的。但即使在你开始写测试之前,你也必须采取准备措施来启用集成测试。在本节中,你将看到这些先决条件:
- Keeping the database in the source control system 将数据库保存在源码控制系统中
- Using a separate database instance for every developer 为每个开发人员使用一个单独的数据库实例
- Applying the migration-based approach to database delivery 应用基于迁移的方法来交付数据库
Like almost everything in testing, though, practices that facilitate testing also improve the health of your database in general. You’ll get value out of those practices even if you don’t write integration tests.
就像测试中的几乎所有事情一样,促进测试的做法也能改善你的数据库的总体健康状况。即使你不写集成测试,你也会从这些实践中获得价值。
10.1.1 Keeping the database in the source control system
将数据库保留在源代码管理系统中
The first step on the way to testing the database is treating the database schema as regular code. Just as with regular code, a database schema is best stored in a source control system such as Git
在测试数据库的道路上,第一步是把数据库schema当作普通代码来对待。就像对待普通代码一样,数据库schema最好保存在源码控制系统中,如Git
I’ve worked on projects where programmers maintained a dedicated database instance, which served as a reference point (a model database). During development, all schema changes accumulated in that instance. Upon production deployments, the team compared the production and model databases, used a special tool to generate upgrade scripts, and ran those scripts in production (figure 10.1).
我曾经在一些项目中工作过,程序员维护一个专门的数据库实例,作为一个参考点(模型数据库)。在开发过程中,所有的模式变化都累积在该实例中。在生产部署时,团队会比较生产数据库和模型数据库,使用一个特殊的工具来生成升级脚本,并在生产中运行这些脚本(图10.1)。
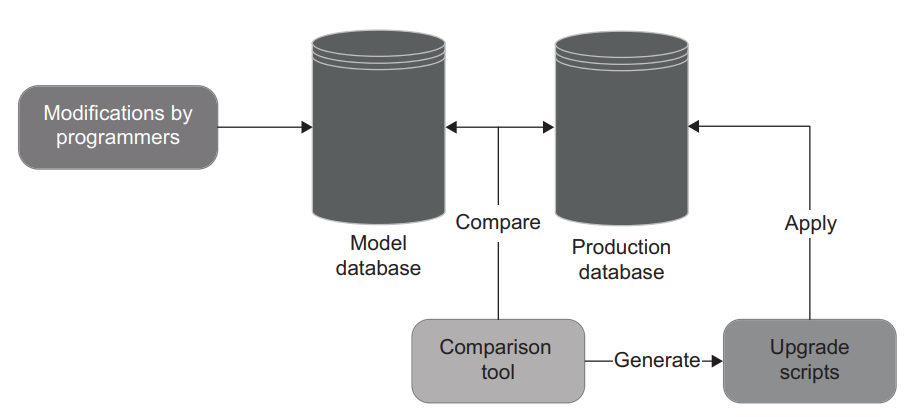
Figure 10.1 Having a dedicated instance as a model database is an anti-pattern. The database schema is best stored in a source control system. 图10.1 将一个专门的实例作为模型数据库是一种反模式。数据库 schema 最好存储在源控制系统中。
Using a model database is a horrible way to maintain database schema. That’s because there’s 使用模型数据库是维护数据库 schema 的一种可怕的方式。这是因为
-
No change history—You can’t trace the database schema back to some point in the past, which might be important when reproducing bugs in production.
没有变化历史—你无法将数据库 schema 追溯到过去的某个时间点,这在生产中重现错误时可能很重要。
-
No single source of truth—The model database becomes a competing source of truth about the state of development. Maintaining two such sources (Git and the model database) creates an additional burden.
没有单一的可信来源—模型数据库成为关于开发状态的一个竞争性可信来源。维护两个这样的来源(Git和模型数据库)会造成额外的负担。
On the other hand, keeping all the database schema updates in the source control system helps you to maintain a single source of truth and also to track database changes along with the changes of regular code. No modifications to the database structure should be made outside of the source control.
另一方面,将所有的数据库 schema 更新保存在源码控制系统中,可以帮助你保持一个单一的可信来源,同时也可以跟踪数据库的变化和常规代码的变化。对数据库结构的修改不应该在源码控制之外进行。
10.1.2 Reference data is part of the database schema
引用数据是数据库schema的一部分
When it comes to the database schema, the usual suspects are tables, views, indexes, stored procedures, and anything else that forms a blueprint of how the database is constructed. The schema itself is represented in the form of SQL scripts. You should be able to use those scripts to create a fully functional, up-to-date database instance of your own at any time during development. However, there’s another part of the database that belongs to the database schema but is rarely viewed as such: reference data.
当涉及到数据库 schema 时,通常的嫌疑人是表、视图、索引、存储过程,以及其他任何形成数据库构造蓝图的东西。schema 本身是以SQL脚本的形式表示的。你应该能够使用这些脚本在开发过程中的任何时候创建一个功能齐全、最新的数据库实例。然而,数据库的另一部分属于数据库 schema ,但很少被视为schema :参考数据。
DEFINITION
Reference data is data that must be prepopulated in order for the application to operate properly.
参考数据是必须预先填充的数据,以使应用程序能够正常运行。
Take the CRM system from the earlier chapters, for example. Its users can be either of type Customer or type Employee. Let’s say that you want to create a table with all user types and introduce a foreign key constraint from User to that table. Such a constraint would provide an additional guarantee that the application won’t ever assign a user a nonexistent type. In this scenario, the content of the UserType table would be reference data because the application relies on its existence in order to persist users in the database.
以前面章节中的CRM系统为例。它的用户可以是客户类型,也可以是雇员类型。假设你想创建一个包含所有用户类型的表,并从用户到该表引入一个外键约束。这样一个约束将提供一个额外的保证,即应用程序不会给用户分配一个不存在的类型。在这种情况下,UserType表的内容将是参考数据,因为应用程序依赖于它的存在,以便在数据库中持久化用户。
TIP
There’s a simple way to differentiate reference data from regular data. If your application can modify the data, it’s regular data; if not, it’s reference data.
有一个简单的方法来区分参考数据和普通数据。如果你的应用程序可以修改这些数据,它就是常规数据;如果不能,它就是参考数据。
Because reference data is essential for your application, you should keep it in the source control system along with tables, views, and other parts of the database schema, in the form of SQL INSERT statements.
因为参考数据对你的应用程序来说是必不可少的,你应该把它和表、视图以及数据库 schema 的其他部分一起,以SQL INSERT语句的形式保存在源控制系统中。
Note that although reference data is normally stored separately from regular data, the two can sometimes coexist in the same table. To make this work, you need to introduce a flag differentiating data that can be modified (regular data) from data that can’t be modified (reference data) and forbid your application from changing the latter.
请注意,尽管参考数据通常与普通数据分开存储,但两者有时可以在同一个表中共存。为了使其发挥作用,你需要引入一个标志,区分可以修改的数据(常规数据)和不能修改的数据(参考数据),并禁止你的应用程序改变后者。
10.1.3 Separate instance for every developer
It’s difficult enough to run tests against a real database. It becomes even more difficult if you have to share that database with other developers. The use of a shared database hinders the development process because
针对一个真实的数据库运行测试已经很困难了。如果你必须与其他开发者共享该数据库,那就更难了。使用共享数据库阻碍了开发过程,因为
- Tests run by different developers interfere with each other. 不同的开发者所运行的测试会相互干扰。
- Non-backward-compatible changes can block the work of other developers. 非后向兼容的变化会阻碍其他开发者的工作。
Keep a separate database instance for every developer, preferably on that developer’s own machine in order to maximize test execution speed. 为每个开发人员保留一个单独的数据库实例,最好是在该开发人员自己的机器上,以便最大限度地提高测试执行速度。
10.1.4 State-based vs. migration-based database delivery
There are two major approaches to database delivery: state-based and migration-based. The migration-based approach is more difficult to implement and maintain initially, but it works much better than the state-based approach in the long run.
有两种主要的数据库交付方法:基于状态和基于迁移。基于迁移的方法在最初实施和维护时比较困难,但从长远来看,它比基于状态的方法好用得多。
THE STATE-BASED APPROACH
The state-based approach to database delivery is similar to what I described in figure 10.1. You also have a model database that you maintain throughout development. During deployments, a comparison tool generates scripts for the production database to bring it up to date with the model database. The difference is that with the statebased approach, you don’t actually have a physical model database as a source of truth. Instead, you have SQL scripts that you can use to create that database. The scripts are stored in the source control.
基于状态的数据库交付方法类似于我在图10.1中描述的方法。你也有一个模型数据库,你在整个开发过程中维护它。在部署过程中,一个比较工具为生产数据库生成脚本,使其与模型数据库保持一致。不同的是,在基于状态的方法中,你实际上没有一个物理模型数据库作为真理的来源。相反,你有SQL脚本,你可以用来创建该数据库。这些脚本被存储在源控制中。
In the state-based approach, the comparison tool does all the hard lifting. Whatever the state of the production database, the tool does everything needed to get it in sync with the model database: delete unnecessary tables, create new ones, rename columns, and so on.
在基于状态的方法中,比较工具做了所有艰苦的工作。无论生产数据库的状态如何,该工具都会做一切必要的工作,使其与模型数据库保持同步:删除不必要的表,创建新的表,重命名列,等等。
THE MIGRATION-BASED APPROACH
On the other hand, the migration-based approach emphasizes the use of explicit migrations that transition the database from one version to another (figure 10.2). With this approach, you don’t use tools to automatically synchronize the production and development databases; you come up with upgrade scripts yourself. However, a database comparison tool can still be useful when detecting undocumented changes in the production database schema.
另一方面,基于迁移的方法强调使用明确的迁移,将数据库从一个版本过渡到另一个版本(图10.2)。采用这种方法,你不使用工具来自动同步生产和开发数据库;你自己想出升级脚本。然而,当检测到生产数据库 schema 中没有记录的变化时,数据库比较工具仍然是有用的。

Figure 10.2 The migration-based approach to database delivery emphasizes the use of explicit migrations that transition the database from one version to another. 图10.2 基于迁移的数据库交付方法强调使用明确的迁移,将数据库从一个版本过渡到另一个版本。
In the migration-based approach, migrations and not the database state become the artifacts you store in the source control. Migrations are usually represented with plain SQL scripts (popular tools include Flyway and Liquibase, but they can also be written using a DSL-like language that gets translated into SQL. The following example shows a C# class that represents a database migration with the help of the FluentMigrator library (https://github.com/ fluentmigrator/fluentmigrator):
在基于迁移的方法中,迁移而不是数据库状态成为你存储在源控制中的工件。迁移通常用普通的SQL脚本来表示(流行的工具包括Flyway和Liquibase),但它们也可以用类似DSL的语言来编写,并被翻译成SQL。下面的例子显示了一个C#类,它在FluentMigrator库的帮助下表示一个数据库迁移:
Listing 10.1. A C# class representing a migration
[Migration(1)] ❶
public class CreateUserTable : Migration
{
public override void Up() ❷
{
Create.Table("Users");
}
public override void Down() ❸
{
Delete.Table("Users");
}
}| ❶ | Migration number |
|---|---|
| ❷ | Forward migration |
| ❸ | Backward migration (helpful when downgrading to an earlier database version to reproduce a bug) |
PREFER THE MIGRATION-BASED APPROACH OVER THE STATE-BASED ONE
The difference between the state-based and migration-based approaches to database delivery comes down to (as their names imply) state versus migrations (see figure 10.3): 基于状态的数据库交付方法和基于迁移的数据库交付方法之间的区别可以归结为(正如它们的名字所暗示的)状态与迁移(见图10.3):
- The state-based approach makes the state explicit (by virtue of storing that state in the source control) and lets the comparison tool implicitly control the migrations. 基于状态的方法将状态显性化(通过在源控制中存储状态),并让比较工具隐式地控制迁移。
- The migration-based approach makes the migrations explicit but leaves the state implicit. It’s impossible to view the database state directly; you have to assemble it from the migrations. 基于迁移的方法使迁移显性化,但使状态隐性化。我们不可能直接查看数据库的状态;你必须通过迁移来组装它。
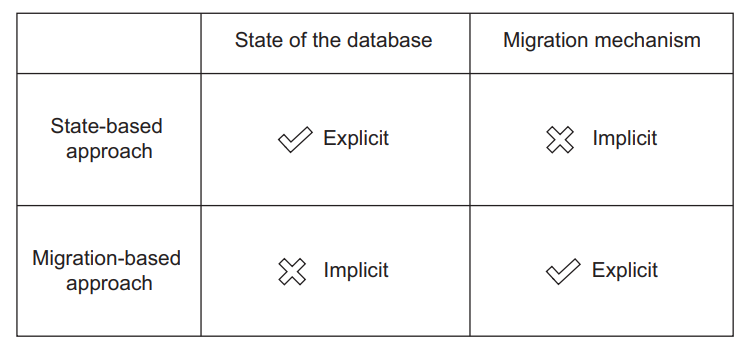
Figure 10.3 The state-based approach makes the state explicit and migrations implicit; the migration-based approach makes the opposite choice. 图10.3 基于状态的方法使状态明确,而迁移隐含;基于迁移的方法则做出了相反的选择。
Such a distinction leads to different sets of trade-offs. The explicitness of the database state makes it easier to handle merge conflicts, while explicit migrations help to tackle data motion.
这样的区别导致了不同的权衡组合。数据库状态的显性使其更容易处理合并冲突,而显性迁移则有助于解决数据运动问题。
DEFINITION
Data motion is the process of changing the shape of existing data so that it conforms to the new database schema.
数据移动是指改变现有数据的形状,使其符合新的数据库 schema 的过程。
Although the alleviation of merge conflicts and the ease of data motion might look like equally important benefits, in the vast majority of projects, data motion is much more important than merge conflicts. Unless you haven’t yet released your application to production, you always have data that you can’t simply discard
尽管缓解合并冲突和简化数据移动看起来是同等重要的好处,但在绝大多数项目中,数据移动比合并冲突要重要得多。除非你还没有把你的应用程序发布到生产中,否则你总是有不能简单丢弃的数据
For example, when splitting a Name column into FirstName and LastName, you not only have to drop the Name column and create the new FirstName and LastName columns, but you also have to write a script to split all existing names into two pieces. There is no easy way to implement this change using the state-driven approach; comparison tools are awful when it comes to managing data. The reason is that while the database schema itself is objective, meaning there is only one way to interpret it, data is context-dependent. No tool can make reliable assumptions about data when generating upgrade scripts. You have to apply domain-specific rules in order to implement proper transformations.
例如,当把一个名字列拆成名字和姓氏时,你不仅要丢弃名字列,创建新的名字和姓氏列,而且还要写一个脚本,把所有现有的名字拆成两块。使用状态驱动的方法来实现这一变化并不容易;在管理数据方面,比较工具是很糟糕的。原因是,虽然数据库 schema 本身是客观的,意味着只有一种方式来解释它,但数据是依赖于上下文的。在生成升级脚本时,没有任何工具能对数据做出可靠的假设。你必须应用特定领域的规则,以实现适当的转换。
As a result, the state-based approach is impractical in the vast majority of projects. You can use it temporarily, though, while the project still has not been released to production. After all, test data isn’t that important, and you can re-create it every time you change the database. But once you release the first version, you will have to switch to the migration-based approach in order to handle data motion properly.
因此,基于状态的方法在绝大多数项目中都是不切实际的。不过,当项目还没有发布到生产中时,你可以暂时使用它。毕竟,测试数据并不那么重要,而且你可以在每次改变数据库时重新创建它。但是一旦你发布了第一个版本,你就必须切换到基于迁移的方法,以便正确处理数据运动。
TIP
Apply every modification to the database schema (including reference data) through migrations. Don’t modify migrations once they are committed to the source control. If a migration is incorrect, create a new migration instead of fixing the old one. Make exceptions to this rule only when the incorrect migration can lead to data loss.
通过迁移来应用对数据库 schema 的每一次修改(包括参考数据)。一旦迁移被提交到源控制中,就不要再修改迁移。如果一个迁移是不正确的,请创建一个新的迁移,而不是修复旧的。只有当错误的迁移会导致数据丢失时,才可以对这一规则进行例外处理。
10.2 Database transaction management
Database transaction management is a topic that’s important for both production and test code. Proper transaction management in production code helps you avoid data inconsistencies. In tests, it helps you verify integration with the database in a close-toproduction setting.
数据库事务管理是一个对生产和测试代码都很重要的话题。生产代码中正确的事务管理可以帮助你避免数据的不一致。在测试中,它可以帮助你在接近生产的情况下验证与数据库的集成。
In this section, I’ll first show how to handle transactions in the production code (the controller) and then demonstrate how to use them in integration tests. I’ll continue using the same CRM project you saw in the earlier chapters as an example.
在本节中,我将首先展示如何在生产代码(控制器)中处理事务,然后演示如何在集成测试中使用它们。我将继续使用你在前面章节中看到的同一个CRM项目作为例子。
10.2.1 Managing database transactions in production code
Our sample CRM project uses the Database class to work with User and Company. Database creates a separate SQL connection on each method call. Every such connection implicitly opens an independent transaction behind the scenes, as the following listing shows.
我们的CRM项目样本使用数据库类来处理用户和公司。数据库在每次方法调用时都会创建一个单独的SQL连接。每一个这样的连接都隐含着在幕后打开一个独立的事务,正如下面的清单所示。
Listing 10.1 Class that enables access to the database
public class Database
{
private readonly string _connectionString;
public Database(string connectionString)
{
_connectionString = connectionString;
}
public void SaveUser(User user)
{
bool isNewUser = user.UserId == 0;
using (var connection =
new SqlConnection(_connectionString)) ❶
{
/* Insert or update the user depending on isNewUser */
}
}
public void SaveCompany(Company company)
{
using (var connection =
new SqlConnection(_connectionString)) ❶
{
/* Update only; there's only one company */
}
}
}As a result, the user controller creates a total of four database transactions during a single business operation, as shown in the following listing.
结果是,用户控制器在一次业务操作中总共创建了四个数据库事务,如下面的列表所示。
Listing 10.2 User controller
public string ChangeEmail(int userId, string newEmail)
{
object[] userData = _database.GetUserById(userId); ❶
User user = UserFactory.Create(userData);
string error = user.CanChangeEmail();
if (error != null)
return error;
object[] companyData = _database.GetCompany(); ❶
Company company = CompanyFactory.Create(companyData);
user.ChangeEmail(newEmail, company);
_database.SaveCompany(company); ❶
_database.SaveUser(user); ❶
_eventDispatcher.Dispatch(user.DomainEvents);
return "OK";
}It’s fine to open multiple transactions during read-only operations: for example, when returning user information to the external client. But if the business operation involves data mutation, all updates taking place during that operation should be atomic in order to avoid inconsistencies. For example, the controller can successfully persist the company but then fail when saving the user due to a database connectivity issue. As a result, the company’s NumberOfEmployees can become inconsistent with the total number of Employee users in the database.
在只读操作中打开多个事务是可以的:例如,在向外部客户返回用户信息时。但是如果业务操作涉及到数据突变,那么在该操作中发生的所有更新应该是原子的,以避免不一致。例如,控制器可以成功地持久化公司,但在保存用户时却由于数据库连接问题而失败。因此,公司的NumberOfEmployees与数据库中的Employee用户总数可能不一致。
DEFINITION
Atomic updates are executed in an all-or-nothing manner. Each update in the set of atomic updates must either be complete in its entirety or have no effect whatsoever.
原子更新是以全有或全无的方式执行的。原子更新集合中的每个更新都必须是完整的,或者没有任何影响。
SEPARATING DATABASE CONNECTIONS FROM DATABASE TRANSACTIONS
To avoid potential inconsistencies, you need to introduce a separation between two types of decisions: 为了避免潜在的不一致,你需要在两种类型的决定之间引入分离:
- What data to update 要更新哪些数据
- Whether to keep the updates or roll them back 是否保留更新或回滚
Such a separation is important because the controller can’t make these decisions simultaneously. It only knows whether the updates can be kept when all the steps in the business operation have succeeded. And it can only take those steps by accessing the database and trying to make the updates. You can implement the separation between these responsibilities by splitting the Database class into repositories and a transaction:
这种分离很重要,因为控制器不能同时做出这些决定。它只知道在业务操作的所有步骤都成功后,是否可以保留更新。而它只能通过访问数据库并尝试进行更新来采取这些步骤。你可以通过将数据库类拆分为Repositories和事务来实现这些职责的分离:
- Repositories are classes that enable access to and modification of the data in the database. There will be two repositories in our sample project: one for User and the other for Company. Repositories是能够访问和修改数据库中的数据的类。在我们的示例项目中会有两个Repositories:一个是用户,另一个是公司。
- A transaction is a class that either commits or rolls back data updates in full. This will be a custom class relying on the underlying database’s transactions to provide atomicity of data modification. 事务是一个类,它可以提交或回滚全部的数据更新。这将是一个自定义的类,依靠底层数据库的事务来提供数据修改的原子性。
Not only do repositories and transactions have different responsibilities, but they also have different lifespans. A transaction lives during the whole business operation and is disposed of at the very end of it. A repository, on the other hand, is short-lived. You can dispose of a repository as soon as the call to the database is completed. As a result, repositories always work on top of the current transaction. When connecting to the database, a repository enlists itself into the transaction so that any data modifications made during that connection can later be rolled back by the transaction.
Repositories和事务不仅有不同的职责,而且它们也有不同的寿命。事务在整个业务操作过程中存在,并在操作结束后被处理掉。而Repositories则是短命的。你可以在对数据库的调用完成后立即处置一个Repositories。因此,Repositories总是在当前事务的基础上工作。当连接到数据库时,Repositories会将自己加入到事务中,这样在连接过程中所做的任何数据修改都可以在以后被事务回滚。
Figure 10.4 shows how the communication between the controller and the database looks in listing 10.2. Each database call is wrapped into its own transaction; updates are not atomic.
图10.4显示了列表10.2中控制器和数据库之间的通信情况。每个数据库调用都被包装成自己的事务;更新不是原子性的。
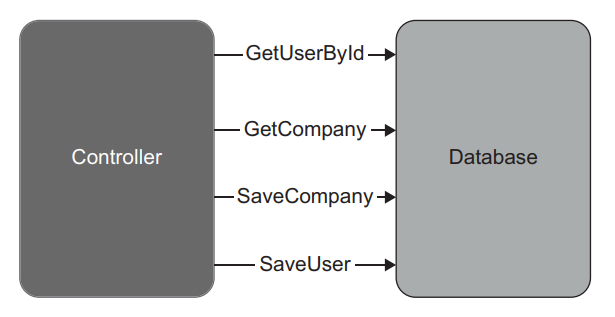
Figure 10.4 Wrapping each database call into a separate transaction introduces a risk of inconsistencies due to hardware or software failures. For example, the application can update the number of employees in the company but not the employees themselves. 图10.4 将每个数据库调用包裹在一个单独的事务中,会带来由于硬件或软件故障而产生的不一致的风险。例如,应用程序可以更新公司的雇员人数,但不能更新雇员本身。
Figure 10.5 shows the application after the introduction of explicit transactions. The transaction mediates interactions between the controller and the database. All four database calls are still there, but now data modifications are either committed or rolled back in full.
图10.5显示了引入显式事务后的应用程序。事务调解了控制器和数据库之间的交互。所有四个数据库调用仍然存在,但现在数据修改要么被提交,要么被全部回滚。
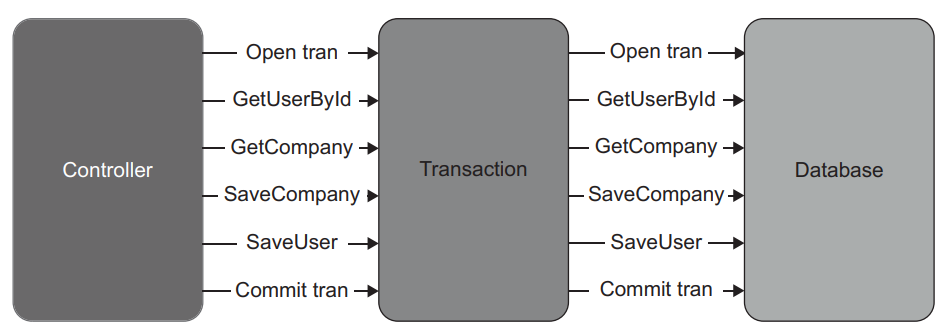
Figure 10.5 The transaction mediates interactions between the controller and the database and thus enables atomic data modification. 图10.5 事务调解了控制器和数据库之间的交互,从而实现了原子数据的修改。
The following listing shows the controller after introducing a transaction and repositories. 下面的清单显示了引入事务和Repositories后的控制器。
Listing 10.3 User controller, repositories, and a transaction
public class UserController
{
private readonly Transaction _transaction;
private readonly UserRepository _userRepository;
private readonly CompanyRepository _companyRepository;
private readonly EventDispatcher _eventDispatcher;
public UserController(
Transaction transaction, ❶
MessageBus messageBus,
IDomainLogger domainLogger)
{
_transaction = transaction;
_userRepository = new UserRepository(transaction);
_companyRepository = new CompanyRepository(transaction);
_eventDispatcher = new EventDispatcher(
messageBus, domainLogger);
}
public string ChangeEmail(int userId, string newEmail)
{
object[] userData = _userRepository ❷
.GetUserById(userId); ❷
User user = UserFactory.Create(userData);
string error = user.CanChangeEmail();
if (error != null)
return error;
object[] companyData = _companyRepository ❷
.GetCompany(); ❷
Company company = CompanyFactory.Create(companyData);
user.ChangeEmail(newEmail, company);
_companyRepository.SaveCompany(company); ❷
_userRepository.SaveUser(user); ❷
_eventDispatcher.Dispatch(user.DomainEvents);
_transaction.Commit(); ❸
return "OK";
}
}
public class UserRepository
{
private readonly Transaction _transaction;
public UserRepository(Transaction transaction) ❹
{
_transaction = transaction;
}
/* ... */
}
public class Transaction : IDisposable
{
public void Commit() { /* ... */ }
public void Dispose() { /* ... */ }
}The internals of the Transaction class aren’t important, but if you’re curious, I’m using .NET’s standard TransactionScope behind the scenes. The important part about Transaction is that it contains two methods:
Transaction类的内部结构并不重要,但如果你感到好奇,我在幕后使用了.NET的标准TransactionScope。关于Transaction的重要部分是它包含两个方法:
- Commit()marks the transaction as successful. This is only called when the business operation itself has succeeded and all data modifications are ready to be persisted. Commit()标志着交易的成功。只有当业务操作本身已经成功,并且所有的数据修改已经准备好被持久化时,才会调用这个方法。
- Dispose()ends the transaction. This is called indiscriminately at the end of the business operation. If Commit() was previously invoked, Dispose() persists all data updates; otherwise, it rolls them back. Dispose()结束事务。它在业务操作结束时被不加区分地调用。如果之前调用了Commit(),Dispose()会持久化所有的数据更新;否则,它会将它们回滚。
Such a combination of Commit() and Dispose() guarantees that the database is altered only during happy paths (the successful execution of the business scenario). That’s why Commit() resides at the very end of the ChangeEmail() method. In the event of any error, be it a validation error or an unhandled exception, the execution flow returns early and thereby prevents the transaction from being committed.
这样一个Commit()和Dispose()的组合保证了数据库只在happy path(业务场景的成功执行)中被改变。这就是为什么Commit()位于ChangeEmail()方法的最末端。如果出现任何错误,无论是验证错误还是未处理的异常,执行流程会提前返回,从而防止事务被提交。
Commit() is invoked by the controller because this method call requires decisionmaking. There’s no decision-making involved in calling Dispose(), though, so you can delegate that method call to a class from the infrastructure layer. The same class that instantiates the controller and provides it with the necessary dependencies should also dispose of the transaction once the controller is done working.
Commit()是由控制器调用的,因为这个方法的调用需要决策。不过,调用Dispose()并不涉及决策,所以你可以把这个方法调用委托给基础设施层的一个类。一旦控制器完成工作,实例化控制器并为其提供必要的依赖关系的同一个类也应该处理掉事务。
Notice how UserRepository requires Transaction as a constructor parameter. This explicitly shows that repositories always work on top of transactions; a repository can’t call the database on its own.
注意UserRepository是如何要求Transaction作为构造函数参数的。这明确地表明,Repositories总是工作在事务之上;Repositories不能自己调用数据库。
UPGRADING THE TRANSACTION TO A UNIT OF WORK
The introduction of repositories and a transaction is a good way to avoid potential data inconsistencies, but there’s an even better approach. You can upgrade the Transaction class to a unit of work.
引入Repositories和事务是避免潜在数据不一致的好方法,但还有一个更好的方法。你可以将事务类升级为工作单元。
DEFINITION
A unit of work maintains a list of objects affected by a business operation. Once the operation is completed, the unit of work figures out all updates that need to be done to alter the database and executes those updates as a single unit (hence the pattern name).
一个工作单元维护一个受业务操作影响的对象的列表。一旦操作完成,工作单元就会计算出所有需要改变数据库的更新,并作为一个单元执行这些更新(因此模式名称)。
The main advantage of a unit of work over a plain transaction is the deferral of updates. Unlike a transaction, a unit of work executes all updates at the end of the business operation, thus minimizing the duration of the underlying database transaction and reducing data congestion (see figure 10.6). Often, this pattern also helps to reduce the number of database calls.
与普通事务相比,工作单元的主要优点是推迟更新。与事务不同,工作单元在业务操作结束时执行所有的更新,从而最大限度地减少底层数据库事务的持续时间,并减少数据拥堵(见图10.6)。通常,这种模式也有助于减少数据库调用的数量。
NOTE
Database transactions also implement the unit-of-work pattern.
数据库事务也实现了工作单元模式。
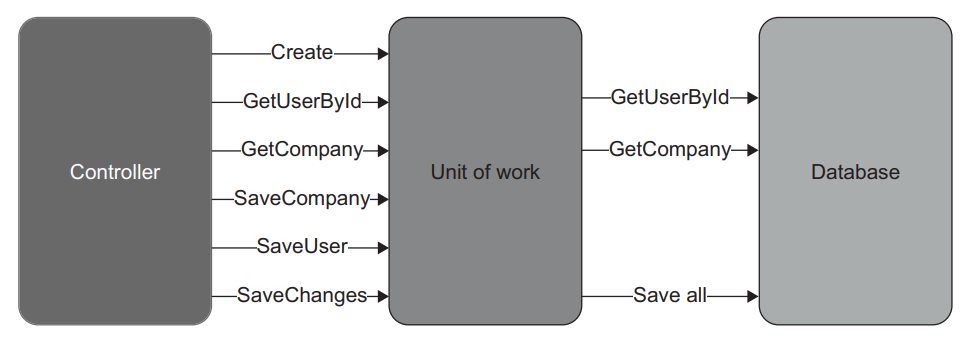
Figure 10.6 A unit of work executes all updates at the end of the business operation. The updates are still wrapped in a database transaction, but that transaction lives for a shorter period of time, thus reducing data congestion. 图10.6 一个工作单元在业务操作结束时执行所有更新。更新仍然被包裹在一个数据库事务中,但该事务存活的时间较短,从而减少了数据拥堵。
Maintaining a list of modified objects and then figuring out what SQL script to generate can look like a lot of work. In reality, though, you don’t need to do that work yourself. Most object-relational mapping (ORM) libraries implement the unit-of-work pattern for you. In .NET, for example, you can use NHibernate or Entity Framework, both of which provide classes that do all the hard lifting (those classes are ISession and DbContext, respectively). The following listing shows how UserController looks in combination with Entity Framework.
维护一个修改过的对象的列表,然后找出要生成的SQL脚本,这看起来是一个很大的工作。但在现实中,你不需要自己做这些工作。大多数对象关系映射(ORM)库为你实现工作单元模式。例如,在.NET中,你可以使用NHibernate或Entity Framework,它们都提供了可以完成所有艰苦工作的类(这些类分别是ISession和DbContext)。下面的列表显示了UserController与Entity Framework的结合情况。
Listing 10.4 User controller with Entity Framework
public class UserController
{
private readonly CrmContext _context;
private readonly UserRepository _userRepository;
private readonly CompanyRepository _companyRepository;
private readonly EventDispatcher _eventDispatcher;
public UserController(
CrmContext context, ❶
MessageBus messageBus,
IDomainLogger domainLogger)
{
_context = context;
_userRepository = new UserRepository(
context); ❶
_companyRepository = new CompanyRepository(
context); ❶
_eventDispatcher = new EventDispatcher(
messageBus, domainLogger);
}
public string ChangeEmail(int userId, string newEmail)
{
User user = _userRepository.GetUserById(userId);
string error = user.CanChangeEmail();
if (error != null)
return error;
Company company = _companyRepository.GetCompany();
user.ChangeEmail(newEmail, company);
_companyRepository.SaveCompany(company);
_userRepository.SaveUser(user);
_eventDispatcher.Dispatch(user.DomainEvents);
_context.SaveChanges(); ❶
return "OK";
}
}CrmContext is a custom class that contains mapping between the domain model and the database (it inherits from Entity Framework’s DbContext). The controller in listing 10.4 uses CrmContext instead of Transaction. As a result,
CrmContext是一个自定义类,它包含领域模型和数据库之间的映射(它继承自Entity Framework的DbContext)。列表10.4中的控制器使用CrmContext而不是Transaction。结果是
- Both repositories now work on top of CrmContext, just as they worked on top of Transaction in the previous version. 两个Repositories现在都在CrmContext之上工作,就像它们在前一个版本中在Transaction之上工作一样。
- The controller commits changes to the database via context.SaveChanges() instead of transaction.Commit(). 控制器通过context.SaveChanges()而不是 transaction.Commit()向数据库提交更改。
Notice that there’s no need for UserFactory and CompanyFactory anymore because Entity Framework now serves as a mapper between the raw database data and domain objects.
注意,不再需要UserFactory和CompanyFactory,因为Entity Framework现在作为原始数据库数据和域对象之间的映射器。
Data inconsistencies in non-relational databases
It’s easy to avoid data inconsistencies when using a relational database: all major relational databases provide atomic updates that can span as many rows as needed. But how do you achieve the same level of protection with a non-relational database such as MongoDB?
在使用关系型数据库时,很容易避免数据不一致:所有主要的关系型数据库都提供原子更新,可以根据需要跨越许多行。但你如何用MongoDB这样的非关系型数据库实现同样的保护水平?
The problem with most non-relational databases is the lack of transactions in the classical sense; atomic updates are guaranteed only within a single document. If a business operation affects multiple documents, it becomes prone to inconsistencies. (In non-relational databases, a document is the equivalent of a row.)
大多数非关系型数据库的问题是缺乏经典意义上的事务;原子更新只在单个文档中得到保证。如果一个业务操作影响到多个文档,就容易出现不一致的情况。(在非关系型数据库中,一个文档相当于一个行)。
Non-relational databases approach inconsistencies from a different angle: they require you to design your documents such that no business operation modifies more than one of those documents at a time. This is possible because documents are more flexible than rows in relational databases. A single document can store data of any shape and complexity and thus capture side effects of even the most sophisticated business operations.
非关系型数据库从不同的角度来处理不一致的问题:它们要求你设计你的文档,使任何业务操作在同一时间都不会修改超过一个文档。这是有可能的,因为文档比关系型数据库中的行更灵活。一个文档可以存储任何形状和复杂程度的数据,从而捕捉到最复杂的业务操作的副作用。
In domain-driven design, there’s a guideline saying that you shouldn’t modify more than one aggregate per business operation. This guideline serves the same goal: protecting you from data inconsistencies. The guideline is only applicable to systems that work with document databases, though, where each document corresponds to one aggregate.
在领域驱动设计中,有一条准则说,你不应该为每个业务操作修改超过一个集合。这条准则的目的是一样的:保护你免受数据不一致的影响。不过,这条准则只适用于使用文档数据库的系统,每个文档对应一个聚合。
10.2.2 Managing database transactions in integration tests
When it comes to managing database transactions in integration tests, adhere to the following guideline: don’t reuse database transactions or units of work between sections of the test. The following listing shows an example of reusing CrmContext in the integration test after switching that test to Entity Framework.
当涉及到在集成测试中管理数据库事务时,请遵守以下准则:不要在测试的各个部分之间重复使用数据库事务或工作单元。下面的列表显示了将该测试切换到Entity Framework后,在集成测试中重复使用CrmContext的例子。
Listing 10.5 Integration test reusing CrmContext
[Fact]
public void Changing_email_from_corporate_to_non_corporate()
{
using (var context = ❶
new CrmContext(ConnectionString)) ❶
{
// Arrange
var userRepository = ❷
new UserRepository(context); ❷
var companyRepository = ❷
new CompanyRepository(context); ❷
var user = new User(0, "user@mycorp.com",
UserType.Employee, false);
userRepository.SaveUser(user);
var company = new Company("mycorp.com", 1);
companyRepository.SaveCompany(company);
context.SaveChanges(); ❷
var busSpy = new BusSpy();
var messageBus = new MessageBus(busSpy);
var loggerMock = new Mock<IDomainLogger>();
var sut = new UserController(
context, ❸
messageBus,
loggerMock.Object);
// Act
string result = sut.ChangeEmail(user.UserId, "new@gmail.com");
// Assert
Assert.Equal("OK", result);
User userFromDb = userRepository ❹
.GetUserById(user.UserId); ❹
Assert.Equal("new@gmail.com", userFromDb.Email);
Assert.Equal(UserType.Customer, userFromDb.Type);
Company companyFromDb = companyRepository ❹
.GetCompany(); ❹
Assert.Equal(0, companyFromDb.NumberOfEmployees);
busSpy.ShouldSendNumberOfMessages(1)
.WithEmailChangedMessage(user.UserId, "new@gmail.com");
loggerMock.Verify(
x => x.UserTypeHasChanged(
user.UserId, UserType.Employee, UserType.Customer),
Times.Once);
}
}This test uses the same instance of CrmContext in all three sections: arrange, act, and assert. This is a problem because such reuse of the unit of work creates an environment that doesn’t match what the controller experiences in production. In production, each business operation has an exclusive instance of CrmContext. That instance is created right before the controller method invocation and is disposed of immediately after.
这个测试在所有三个部分都使用了CrmContext的同一个实例:安排、行动和断言。这是一个问题,因为这种工作单元的重复使用创造了一个与控制器在生产中所经历的不一致的环境。在生产中,每个业务操作都有一个CrmContext的专属实例。该实例在控制器方法调用前被创建,并在调用后立即被处置。
To avoid the risk of inconsistent behavior, integration tests should replicate the production environment as closely as possible, which means the act section must not share CrmContext with anyone else. The arrange and assert sections must get their own instances of CrmContext too, because, as you might remember from chapter 8, it’s important to check the state of the database independently of the data used as input parameters. And although the assert section does query the user and the company independently of the arrange section, these sections still share the same database context. That context can (and many ORMs do) cache the requested data for performance improvements.
为了避免行为不一致的风险,集成测试应该尽可能地复制生产环境,这意味着act部分不能与其他任何人共享CrmContext。arrange 和 assert 部分也必须获得他们自己的 CrmContext 实例,因为,正如你可能记得的第 8 章,检查数据库的状态与作为输入参数的数据无关是很重要的。尽管断言部分独立于安排部分查询用户和公司,但这些部分仍然共享同一个数据库上下文。该上下文可以(许多ORM也是如此)缓存所请求的数据以提高性能。
TIP
Use at least three transactions or units of work in an integration test: one per each arrange, act, and assert section.
在集成测试中至少使用三个事务或工作单元:每个安排、行动和断言部分各一个。
10.3 Test data life cycle
The shared database raises the problem of isolating integration tests from each other. To solve this problem, you need to 共享数据库引起了将集成测试相互隔离的问题。为了解决这个问题,你需要
- Execute integration tests sequentially. 按顺序执行集成测试。
- Remove leftover data between test runs. 在测试运行之间删除剩余的数据。
Overall, your tests shouldn’t depend on the state of the database. Your tests should bring that state to the required condition on their own.
总之,你的测试不应该依赖于数据库的状态。你的测试应该自己把这个状态带到所需的条件。
10.3.1 Parallel vs. sequential test execution
Parallel execution of integration tests involves significant effort. You have to ensure that all test data is unique so no database constraints are violated and tests don’t accidentally pick up input data after each other. Cleaning up leftover data also becomes trickier. It’s more practical to run integration tests sequentially rather than spend time trying to squeeze additional performance out of them.
集成测试的并行执行涉及大量的工作。你必须确保所有的测试数据是唯一的,这样就不会违反数据库的约束,测试也不会意外地在彼此之后拾取输入数据。清理遗留的数据也变得更加棘手。按顺序运行集成测试比花时间从他们身上榨取额外的性能更实际。
Most unit testing frameworks allow you to define separate test collections and selectively disable parallelization in them. Create two such collections (for unit and integration tests), and then disable test parallelization in the collection with the integration tests.
大多数单元测试框架允许你定义单独的测试集合,并有选择地禁用其中的并行化。创建两个这样的集合(用于单元测试和集成测试),然后在集成测试的集合中禁用测试并行化。
As an alternative, you could parallelize tests using containers. For example, you could put the model database on a Docker image and instantiate a new container from that image for each integration test. In practice, though, this approach creates too much of an additional maintenance burden. With Docker, you not only have to keep track of the database itself, but you also need to
作为一种选择,你可以使用容器来并行化测试。例如,你可以把模型数据库放在一个Docker镜像上,并为每个集成测试从该镜像实例化一个新的容器。但在实践中,这种方法造成了太多的额外维护负担。使用Docker,你不仅要跟踪数据库本身,而且还需要
- Maintain Docker images 维护Docker镜像
- Make sure each test gets its own container instance 确保每个测试都得到自己的容器实例
- Batch integration tests (because you most likely won’t be able to create all container instances at once) 批量集成测试(因为你很可能无法一次创建所有的容器实例)
- Dispose of used-up containers 处置用过的容器
I don’t recommend using containers unless you absolutely need to minimize your integration tests’ execution time. Again, it’s more practical to have just one database instance per developer. You can run that single instance in Docker, though. I advocate against premature parallelization, not the use of Docker perse.
我不建议使用容器,除非你绝对需要尽量减少集成测试的执行时间。同样,每个开发人员只拥有一个数据库实例是比较实际的。不过,你可以在Docker中运行这个单一的实例。我主张反对过早的并行化,而不是使用Docker本身。
10.3.2 Clearing data between test runs
There are four options to clean up leftover data between test runs: 有四种方案可以清理测试运行之间的遗留数据:
- Restoring a database backup before each test—This approach addresses the problem of data cleanup but is much slower than the other three options. Even with containers, the removal of a container instance and creation of a new one usually takes several seconds, which quickly adds to the total test suite execution time. 在每次测试前恢复数据库备份—这种方法解决了数据清理的问题,但比其他三种方法慢得多。即使是容器,移除一个容器实例并创建一个新的实例通常需要几秒钟,这很快就会增加测试套件的总执行时间。
- Cleaning up data at the end of a test—This method is fast but susceptible to skipping the cleanup phase. If the build server crashes in the middle of the test, or you shut down the test in the debugger, the input data remains in the database and affects further test runs. 在测试结束时清理数据—这种方法很快,但容易跳过清理阶段。如果构建服务器在测试过程中崩溃,或者你在调试器中关闭了测试,输入的数据就会留在数据库中,影响进一步的测试运行。
- Wrapping each test in a database transaction and never committing it—In this case, all changes made by the test and the SUT are rolled back automatically. This approach solves the problem of skipping the cleanup phase but poses another issue: the introduction of an overarching transaction can lead to inconsistent behavior between the production and test environments. It’s the same problem as with reusing a unit of work: the additional transaction creates a setup that’s different than that in production. 将每个测试包裹在数据库事务中,永远不提交—在这种情况下,测试和SUT所做的所有改变都会自动回滚。这种方法解决了跳过清理阶段的问题,但带来了另一个问题:引入总体事务会导致生产和测试环境之间的行为不一致。这和重用一个工作单元的问题一样:额外的事务创造了一个与生产环境不同的设置。
- Cleaning up data at the beginning of a test—This is the best option. It works fast, doesn’t result in inconsistent behavior, and isn’t prone to accidentally skipping the cleanup phase. 在测试开始时清理数据—这是最好的选择。它工作速度快,不会导致不一致的行为,而且不容易意外地跳过清理阶段。
TIP
There’s no need for a separate teardown phase; implement that phase as part of the arrange section.
不需要单独的拆解阶段;把这个阶段作为安排部分的一部分来实现。
The data removal itself must be done in a particular order, to honor the database’s foreign key constraints. I sometimes see people use sophisticated algorithms to figure out relationships between tables and automatically generate the deletion script or even disable all integrity constraints and re-enable them afterward. This is unnecessary. Write the SQL script manually: it’s simpler and gives you more granular control over the deletion process.
数据删除本身必须以特定的顺序进行,以尊重数据库的外键约束。我有时看到有人使用复杂的算法来计算表之间的关系,并自动生成删除脚本,甚至禁用所有的完整性约束,并在之后重新启用它们。这是不需要的。手动编写SQL脚本:它更简单,而且让你对删除过程有更细微的控制。
Introduce a base class for all integration tests, and put the deletion script there. With such a base class, you will have the script run automatically at the start of each test, as shown in the following listing.
为所有的集成测试引入一个基类,并把删除脚本放在那里。有了这样一个基类,你将在每个测试开始时自动运行脚本,如下面的列表所示。
Listing 10.6 Base class for integration tests
public abstract class IntegrationTests
{
private const string ConnectionString = "...";
protected IntegrationTests()
{
ClearDatabase();
}
private void ClearDatabase()
{
string query =
"DELETE FROM dbo.[User];" + ❶
"DELETE FROM dbo.Company;"; ❶
using (var connection = new SqlConnection(ConnectionString))
{
var command = new SqlCommand(query, connection)
{
CommandType = CommandType.Text
};
connection.Open();
command.ExecuteNonQuery();
}
}
}TIP
The deletion script must remove all regular data but none of the reference data. Reference data, along with the rest of the database schema, should be controlled solely by migrations.
删除脚本必须删除所有的常规数据,但不包括参考数据。参考数据,以及数据库 schema 的其他部分,应该只由迁移来控制。
10.3.3 Avoid in-memory databases
Another way to isolate integration tests from each other is by replacing the database with an in-memory analog, such as SQLite. In-memory databases can seem beneficial because they 另一种将集成测试相互隔离的方法是将数据库替换为内存中的类似物,如SQLite。内存数据库似乎是有益的,因为它们
- Don’t require removal of test data 不需要删除测试数据
- Work faster 工作速度更快
- Can be instantiated for each test run 可以为每个测试运行实例化
Because in-memory databases aren’t shared dependencies, integration tests in effect become unit tests (assuming the database is the only managed dependency in the project), similar to the approach with containers described in section 10.3.1.
因为内存数据库不是共享的依赖,集成测试实际上成为单元测试(假设数据库是项目中唯一的管理依赖),类似于10.3.1节中描述的容器的方法。
In spite of all these benefits, I don’t recommend using in-memory databases because they aren’t consistent functionality-wise with regular databases. This is, once again, the problem of a mismatch between production and test environments. Your tests can easily run into false positives or (worse!) false negatives due to the differences between the regular and in-memory databases. You’ll never gain good protection with such tests and will have to do a lot of regression testing manually anyway.
尽管有这些好处,我并不推荐使用内存数据库,因为它们在功能上与普通数据库不一致。这又是生产和测试环境不匹配的问题。由于常规数据库和内存数据库之间的差异,你的测试很容易遇到假阳性或(更糟糕!)假阴性。通过这样的测试,你永远不会获得良好的保护,而且无论如何都要手动进行大量的回归测试。
TIP
Use the same database management system (DBMS) in tests as in production. It’s usually fine for the version or edition to differ, but the vendor must remain the same.
在测试中使用与生产中相同的数据库管理系统(DBMS)。通常版本或版本不同是可以的,但供应商必须保持不变。
10.4 Reusing code in test sections
Integration tests can quickly grow too large and thus lose ground on the maintainability metric. It’s important to keep integration tests as short as possible but without coupling them to each other or affecting readability. Even the shortest tests shouldn’t depend on one another. They also should preserve the full context of the test scenario and shouldn’t require you to examine different parts of the test class to understand what’s going on.
集成测试很快就会变得过于庞大,从而在可维护性指标上失去优势。重要的是要使集成测试尽可能的短,但不要让它们相互耦合或影响可读性。即使是最短的测试也不应该相互依赖。他们也应该保留测试场景的完整上下文,不应该要求你检查测试类的不同部分来了解发生了什么。
The best way to shorten integration is by extracting technical, non-business-related bits into private methods or helper classes. As a side bonus, you’ll get to reuse those bits. In this section, I’ll show how to shorten all three sections of the test: arrange, act, and assert.
缩短集成的最好方法是将技术性的、与业务无关的部分提取到私有方法或辅助类中。作为一个附带的好处,你可以重用这些部分。在本节中,我将展示如何缩短测试的所有三个部分:安排、行动和断言。
10.4.1 Reusing code in arrange sections
The following listing shows how our integration test looks after providing a separate database context (unit of work) for each of its sections.
下面的列表显示了我们的集成测试在为每个部分提供单独的数据库上下文(工作单元)后的样子。
Listing 10.7 Integration test with three database contexts
[Fact]
public void Changing_email_from_corporate_to_non_corporate()
{
// Arrange
User user;
using (var context = new CrmContext(ConnectionString))
{
var userRepository = new UserRepository(context);
var companyRepository = new CompanyRepository(context);
user = new User(0, "user@mycorp.com",
UserType.Employee, false);
userRepository.SaveUser(user);
var company = new Company("mycorp.com", 1);
companyRepository.SaveCompany(company);
context.SaveChanges();
}
var busSpy = new BusSpy();
var messageBus = new MessageBus(busSpy);
var loggerMock = new Mock<IDomainLogger>();
string result;
using (var context = new CrmContext(ConnectionString))
{
var sut = new UserController(
context, messageBus, loggerMock.Object);
// Act
result = sut.ChangeEmail(user.UserId, "new@gmail.com");
}
// Assert
Assert.Equal("OK", result);
using (var context = new CrmContext(ConnectionString))
{
var userRepository = new UserRepository(context);
var companyRepository = new CompanyRepository(context);
User userFromDb = userRepository.GetUserById(user.UserId);
Assert.Equal("new@gmail.com", userFromDb.Email);
Assert.Equal(UserType.Customer, userFromDb.Type);
Company companyFromDb = companyRepository.GetCompany();
Assert.Equal(0, companyFromDb.NumberOfEmployees);
busSpy.ShouldSendNumberOfMessages(1)
.WithEmailChangedMessage(user.UserId, "new@gmail.com");
loggerMock.Verify(
x => x.UserTypeHasChanged(
user.UserId, UserType.Employee, UserType.Customer),
Times.Once);
}
}As you might remember from chapter 3, the best way to reuse code between the tests’ arrange sections is to introduce private factory methods. For example, the following listing creates a user.
你可能还记得第三章,在测试的安排部分之间重用代码的最好方法是引入私有工厂方法。例如,下面的列表创建了一个用户。
Listing 10.8 A separate method that creates a user
private User CreateUser(
string email, UserType type, bool isEmailConfirmed)
{
using (var context = new CrmContext(ConnectionString))
{
var user = new User(0, email, type, isEmailConfirmed);
var repository = new UserRepository(context);
repository.SaveUser(user);
context.SaveChanges();
return user;
}
}You can also define default values for the method’s arguments, as shown next. 你还可以为方法的参数定义默认值,如下所示。
Listing 10.9 Adding default values to the factory
private User CreateUser(
string email = "user@mycorp.com",
UserType type = UserType.Employee,
bool isEmailConfirmed = false)
{
/* ... */
}With default values, you can specify arguments selectively and thus shorten the test even further. The selective use of arguments also emphasizes which of those arguments are relevant to the test scenario.
通过默认值,你可以有选择地指定参数,从而进一步缩短测试时间。有选择地使用参数还可以强调这些参数中哪些是与测试场景相关的。
Listing 10.10 Using the factory method
User user = CreateUser(
email: "user@mycorp.com",
type: UserType.Employee);Object Mother vs. Test Data Builder
The pattern shown in listings 10.9 and 10.10 is called the Object Mother. The Object Mother is a class or method that helps create test fixtures (objects the test runs against).
在列表10.9和10.10中显示的模式被称为Object Mother。Object Mother是一个类或方法,帮助创建测试夹具(测试运行的对象)。
There’s another pattern that helps achieve the same goal of reusing code in arrange sections: Test Data Builder. It works similarly to Object Mother but exposes a fluent interface instead of plain methods. Here’s a Test Data Builder usage example:
还有另一种模式,有助于实现在安排部分重复使用代码的相同目标: 测试数据生成器。它的工作原理与Object Mother类似,但暴露了一个流畅的接口而不是普通的方法。下面是一个测试数据生成器的使用例子:
User user = new UserBuilder() .WithEmail("user@mycorp.com") .WithType(UserType.Employee) .Build();Test Data Builder slightly improves test readability but requires too much boilerplate. For that reason, I recommend sticking to the Object Mother (at least in C#, where you have optional arguments as a language feature).
测试数据生成器稍微提高了测试的可读性,但需要太多的模板。出于这个原因,我建议坚持使用 “Object Mother”(至少在C#中是这样的,在那里你可以把可选参数作为一种语言特性)。
WHERE TO PUT FACTORY METHODS
When you start distilling the tests’ essentials and move the technicalities out to factory methods, you face the question of where to put those methods. Should they reside in the same class as the tests? The base IntegrationTests class? Or in a separate helper class?
当你开始提炼测试的精华,并将技术性的东西转移到工厂方法中时,你会面临将这些方法放在哪里的问题。它们应该和测试放在同一个类中吗?基础 IntegrationTests 类?还是在一个单独的辅助类中?
Start simple. Place the factory methods in the same class by default. Move them into separate helper classes only when code duplication becomes a significant issue. Don’t put the factory methods in the base class; reserve that class for code that has to run in every test, such as data cleanup.
开始时很简单。默认情况下,将工厂方法放在同一个类中。只有当代码重复成为一个重要问题时,才把它们移到单独的辅助类中。不要把工厂方法放在基类中;将该类保留给必须在每个测试中运行的代码,如数据清理。
10.4.2 Reusing code in act sections
Every act section in integration tests involves the creation of a database transaction or a unit of work. This is how the act section currently looks in listing 10.7:
集成测试中的每个行为部分都涉及到创建一个数据库事务或工作单元。这就是列表10.7中行为部分目前的样子:
string result;
using (var context = new CrmContext(ConnectionString))
{
var sut = new UserController(
context, messageBus, loggerMock.Object);
// Act
result = sut.ChangeEmail(user.UserId, "new@gmail.com");
}This section can also be reduced. You can introduce a method accepting a delegate with the information of what controller function needs to be invoked. The method will then decorate the controller invocation with the creation of a database context, as shown in the following listing.
这一部分也可以减少。你可以引入一个方法,接受一个带有需要调用的控制器功能信息的委托。然后,该方法将用创建数据库上下文来装饰控制器的调用,如下面的列表所示。
Listing 10.11 Decorator method
private string Execute(
Func<UserController, string> func, ❶
MessageBus messageBus,
IDomainLogger logger)
{
using (var context = new CrmContext(ConnectionString))
{
var controller = new UserController(
context, messageBus, logger);
return func(controller);
}
}With this decorator method, you can boil down the test’s act section to just a couple of lines: 通过这种装饰方法,你可以将测试的行为部分简化为几行:
string result = Execute(
x => x.ChangeEmail(user.UserId, "new@gmail.com"),
messageBus, loggerMock.Object);10.4.3 Reusing code in assert sections
Finally, the assert section can be shortened, too. The easiest way to do that is to introduce helper methods similar to CreateUser and CreateCompany, as shown in the following listing.
最后,断言部分也可以被缩短。最简单的方法是引入类似于CreateUser和CreateCompany的辅助方法,如以下列表所示。
Listing 10.12 Data assertions after extracting the querying logic
User userFromDb = QueryUser(user.UserId); // New helper methods
Assert.Equal("new@gmail.com", userFromDb.Email);
Assert.Equal(UserType.Customer, userFromDb.Type);
Company companyFromDb = QueryCompany(); // New helper methods
Assert.Equal(0, companyFromDb.NumberOfEmployees);You can take a step further and create a fluent interface for these data assertions, similar to what you saw in chapter 9 with BusSpy. In C#, a fluent interface on top of existing domain classes can be implemented using extension methods, as shown in the following listing.
你可以更进一步,为这些数据断言创建一个流畅的接口,类似于你在第9章中看到的BusSpy的情况。在C#中,现有领域类之上的流畅接口可以使用扩展方法来实现,如以下清单所示。
Listing 10.13 Fluent interface for data assertions
public static class UserExternsions
{
public static User ShouldExist(this User user)
{
Assert.NotNull(user);
return user;
}
public static User WithEmail(this User user, string email)
{
Assert.Equal(email, user.Email);
return user;
}
}With this fluent interface, the assertions become much easier to read: 有了这个流畅的接口,断言变得更容易阅读:
User userFromDb = QueryUser(user.UserId);
userFromDb
.ShouldExist()
.WithEmail("new@gmail.com")
.WithType(UserType.Customer);
Company companyFromDb = QueryCompany();
companyFromDb
.ShouldExist()
.WithNumberOfEmployees(0);10.4.4 Does the test create too many database transactions?
After all the simplifications made earlier, the integration test has become more readable and, therefore, more maintainable. There’s one drawback, though: the test now uses a total of five database transactions (units of work), where before it used only three, as shown in the following listing.
经过前面所有的简化,集成测试已经变得更加可读,因此也更容易维护。但有一个缺点:测试现在总共使用了五个数据库事务(工作单位),而之前只使用了三个,如下面的列表所示。
Listing 10.14 Integration test after moving all technicalities out of it
public class UserControllerTests : IntegrationTests
{
[Fact]
public void Changing_email_from_corporate_to_non_corporate()
{
// Arrange
User user = CreateUser( ❶
email: "user@mycorp.com",
type: UserType.Employee);
CreateCompany("mycorp.com", 1); ❶
var busSpy = new BusSpy();
var messageBus = new MessageBus(busSpy);
var loggerMock = new Mock<IDomainLogger>();
// Act
string result = Execute( ❶
x => x.ChangeEmail(user.UserId, "new@gmail.com"),
messageBus, loggerMock.Object);
// Assert
Assert.Equal("OK", result);
User userFromDb = QueryUser(user.UserId); ❶
userFromDb
.ShouldExist()
.WithEmail("new@gmail.com")
.WithType(UserType.Customer);
Company companyFromDb = QueryCompany(); ❶
companyFromDb
.ShouldExist()
.WithNumberOfEmployees(0);
busSpy.ShouldSendNumberOfMessages(1)
.WithEmailChangedMessage(user.UserId, "new@gmail.com");
loggerMock.Verify(
x => x.UserTypeHasChanged(
user.UserId, UserType.Employee, UserType.Customer),
Times.Once);
}
}Is the increased number of database transactions a problem? And, if so, what can you do about it? The additional database contexts are a problem to some degree because they make the test slower, but there’s not much that can be done about it. It’s another example of a trade-off between different aspects of a valuable test: this time between fast feedback and maintainability. It’s worth it to make that trade-off and exchange performance for maintainability in this particular case. The performance degradation shouldn’t be that significant, especially when the database is located on the developer’s machine. At the same time, the gains in maintainability are quite substantial.
数据库事务数量的增加是一个问题吗?如果是的话,你能做什么?额外的数据库上下文在某种程度上是个问题,因为它们使测试变得更慢,但对此没有什么可以做的。这是在一个有价值的测试的不同方面进行权衡的另一个例子:这次是在快速反馈和可维护性之间。在这种特殊情况下,做出这种权衡并以性能换取可维护性是值得的。性能的下降不应该那么明显,特别是当数据库位于开发者的机器上时。同时,可维护性方面的收益也是相当可观的。
10.5 Common database testing questions
In this last section of the chapter, I’d like to answer common questions related to database testing, as well as briefly reiterate some important points made in chapters 8 and 9.
在本章的最后一节,我想回答与数据库测试有关的常见问题,并简要重申第8章和第9章中的一些重要观点。
10.5.1 Should you test reads?
Throughout the last several chapters, we’ve worked with a sample scenario of changing a user email. This scenario is an example of a write operation (an operation that leaves a side effect in the database and other out-of-process dependencies). Most applications contain both write and read operations. An example of a read operation would be returning the user information to the external client. Should you test both writes and reads?
在过去的几章中,我们已经使用了一个更改用户电子邮件的示例场景。这个场景是一个写操作的例子(一个会在数据库和其他进程外依赖中留下副作用的操作)。大多数应用程序都包含写和读操作。读操作的一个例子是将用户信息返回给外部客户。你应该同时测试写和读吗?
It’s crucial to thoroughly test writes, because the stakes are high. Mistakes in write operations often lead to data corruption, which can affect not only your database but also external applications. Tests that cover writes are highly valuable due to the protection they provide against such mistakes.
彻底测试写操作是很关键的,因为风险很大。写操作中的错误往往会导致数据损坏,这不仅会影响到你的数据库,也会影响到外部应用程序。涵盖写操作的测试是非常有价值的,因为它们提供了对这种错误的保护。
This is not the case for reads: a bug in a read operation usually doesn’t have consequences that are as detrimental. Therefore, the threshold for testing reads should be higher than that for writes. Test only the most complex or important read operations; disregard the rest.
读取的情况则不同:读取操作中的错误通常不会产生如此有害的后果。因此,测试读的门槛应该比写的门槛高。只测试最复杂或最重要的读操作;其余的就不要考虑了。
Note that there’s also no need for a domain model in reads. One of the main goals of domain modeling is encapsulation. And, as you might remember from chapters 5 and 6, encapsulation is about preserving data consistency in light of any changes. The lack of data changes makes encapsulation of reads pointless. In fact, you don’t need a fully fledged ORM such as NHibernate or Entity Framework in reads, either. You are better off using plain SQL, which is superior to an ORM performance-wise, thanks to bypassing unnecessary layers of abstraction (figure 10.7).
注意,在读中也不需要领域模型。领域建模的主要目标之一是封装。而且,你可能还记得第5章和第6章的内容,封装是为了在任何变化的情况下保持数据的一致性。缺乏数据变化使得对读的封装毫无意义。事实上,你也不需要一个成熟的ORM,如NHibernate或Entity Framework,在读取中。你最好使用普通的SQL,由于绕过了不必要的抽象层,它的性能优于ORM(图10.7)。
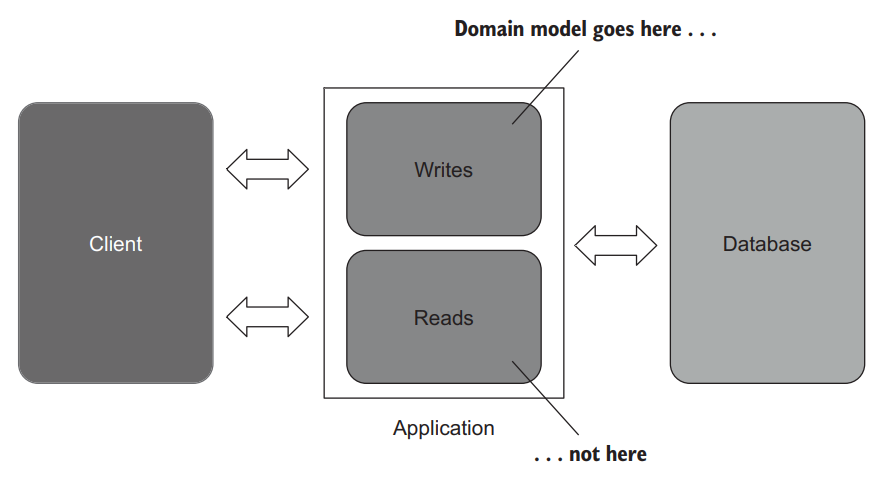
Figure 10.7 There’s no need for a domain model in reads. And because the cost of a mistake in reads is lower than it is in writes, there’s also not as much need for integration testing. 图10.7 读取时不需要领域模型。因为在读中出错的成本比写中低,所以也不需要进行集成测试。
Because there are hardly any abstraction layers in reads (the domain model is one such layer), unit tests aren’t of any use there. If you decide to test your reads, do so using integration tests on a real database.
因为在读中几乎没有任何抽象层(领域模型就是这样一个层),所以单元测试在这里没有任何用处。如果你决定测试你的读,请在一个真实的数据库上使用集成测试来完成。
10.5.2 Should you test repositories?
Repositories provide a useful abstraction on top of the database. Here’s a usage example from our sample CRM project:
Repositories在数据库的基础上提供了一个有用的抽象概念。下面是我们的CRM项目样本中的一个使用例子:
User user = _userRepository.GetUserById(userId);
_userRepository.SaveUser(user);Should you test repositories independently of other integration tests? It might seem beneficial to test how repositories map domain objects to the database. After all, there’s significant room for a mistake in this functionality. Still, such tests are a net loss to your test suite due to high maintenance costs and inferior protection against regressions. Let’s discuss these two drawbacks in more detail.
你应该独立于其他集成测试来测试Repositories吗?测试Repositories如何将域对象映射到数据库中似乎是有益的。毕竟,在这个功能上有很大的出错空间。然而,这样的测试对你的测试套件来说是一个净损失,因为维护成本高,对回归的保护程度低。让我们更详细地讨论这两个缺点。
HIGH MAINTENANCE COSTS
Repositories fall into the controllers quadrant on the types-of-code diagram from chapter 7 (figure 10.8). They exhibit little complexity and communicate with an outof-process dependency: the database. The presence of that out-of-process dependency is what inflates the tests’ maintenance costs.
Repositories属于第七章代码类型图中的控制者象限(图10.8)。它们表现出很少的复杂性,并与进程外的依赖关系:数据库进行通信。这种过程外的依赖性的存在,使测试的维护成本上升。
When it comes to maintenance costs, testing repositories carries the same burden as regular integration tests. But does such testing provide an equal amount of benefits in return? Unfortunately, it doesn’t. 当涉及到维护成本时,测试repositories的负担与常规集成测试相同。但是,这样的测试是否提供了同等数量的利益回报?不幸的是,它并没有。
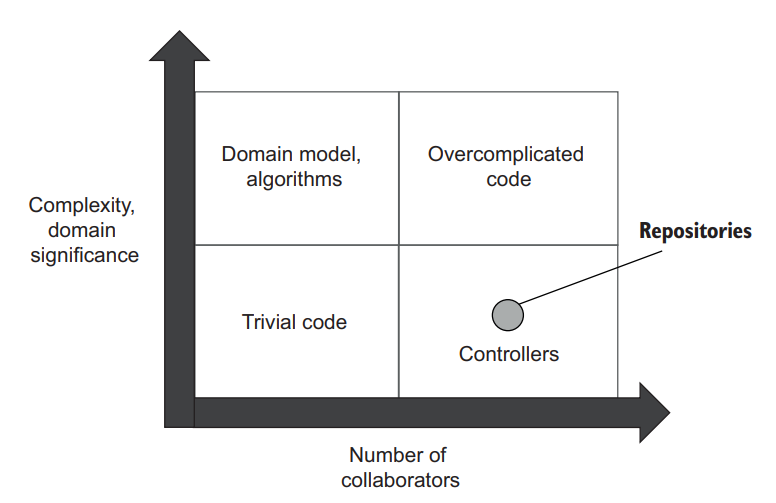
Figure 10.8 Repositories exhibit little complexity and communicate with the out-of-process dependency, thus falling into the controllers quadrant on the types-of-code diagram. 图10.8 Repositories表现出很少的复杂性,并与进程外的依赖关系进行通信,因此属于代码类型图上的控制者象限。
INFERIOR PROTECTION AGAINST REGRESSIONS
Repositories don’t carry that much complexity, and a lot of the gains in protection against regressions overlap with the gains provided by regular integration tests. Thus, tests on repositories don’t add significant enough value.
Repositories没有那么多的复杂性,而且在保护回归方面的很多收益与常规集成测试提供的收益相重叠。因此,对Repositories的测试并没有增加足够大的价值。
The best course of action in testing a repository is to extract the little complexity it has into a self-contained algorithm and test that algorithm exclusively. That’s what UserFactory and CompanyFactory were for in earlier chapters. These two classes performed all the mappings without taking on any collaborators, out-of-process or otherwise. The repositories (the Database class) only contained simple SQL queries.
测试Repositories的最好方法是把它的少量复杂性提取到一个独立的算法中,然后专门测试这个算法。这就是前几章中UserFactory和CompanyFactory的作用。这两个类执行了所有的映射,而没有接受任何合作者,不管是进程外的还是其他的。Repositories(数据库类)只包含简单的SQL查询。
Unfortunately, such a separation between data mapping (formerly performed by the factories) and interactions with the database (formerly performed by Database) is impossible when using an ORM. You can’t test your ORM mappings without calling the database, at least not without compromising resistance to refactoring. Therefore, adhere to the following guideline: don’t test repositories directly, only as part of the overarching integration test suite.
不幸的是,在使用ORM时,数据映射(以前由工厂执行)和与数据库的交互(以前由数据库执行)之间的这种分离是不可能的。你不能在不调用数据库的情况下测试你的ORM映射,至少不能在不影响抗重构的情况下。因此,遵守以下准则:不要直接测试Repositories,只作为总体集成测试套件的一部分。
Don’t test EventDispatcher separately, either (this class converts domain events into calls to unmanaged dependencies). There are too few gains in protection against regressions in exchange for the too-high costs required to maintain the complicated mock machinery.
也不要单独测试EventDispatcher(该类将领域事件转换为对非管理依赖的调用)。在保护回归方面的收益太少,以换取维护复杂的模拟机制所需的过高成本。
10.6 Conclusion
Well-crafted tests against the database provide bulletproof protection from bugs. In my experience, they are one of the most effective tools, without which it’s impossible to gain full confidence in your software. Such tests help enormously when you refactor the database, switch the ORM, or change the database vendor.
针对数据库的精心设计的测试提供了对错误的防弹保护。根据我的经验,它们是最有效的工具之一,没有它们,就不可能对你的软件获得充分的信心。当你重构数据库、更换ORM或改变数据库供应商时,这样的测试有很大的帮助。
In fact, our sample project transitioned to the Entity Framework ORM earlier in this chapter, and I only needed to modify a couple of lines of code in the integration test to make sure the transition was successful. Integration tests working directly with managed dependencies are the most efficient way to protect against bugs resulting from large-scale refactorings.
事实上,我们的示例项目在本章前面过渡到了Entity Framework ORM,而我只需要在集成测试中修改几行代码就可以确保过渡成功了。直接与被管理的依赖关系一起工作的集成测试是防止大规模重构导致的错误的最有效方法。
Summary
-
Store database schema in a source control system, along with your source code. Database schema consists of tables, views, indexes, stored procedures, and anything else that forms a blueprint of how the database is constructed.
-
Reference data is also part of the database schema. It is data that must be prepopulated in order for the application to operate properly. To differentiate between reference and regular data, look at whether your application can modify that data. If so, it’s regular data; otherwise, it’s reference data.
-
Have a separate database instance for every developer. Better yet, host that instance on the developer’s own machine for maximum test execution speed.
-
The state-based approach to database delivery makes the state explicit and lets a comparison tool implicitly control migrations. The migration-based approach emphasizes the use of explicit migrations that transition the database from one state to another. The explicitness of the database state makes it easier to handle merge conflicts, while explicit migrations help tackle data motion.
-
Prefer the migration-based approach over state-based, because handling data motion is much more important than merge conflicts. Apply every modification to the database schema (including reference data) through migrations.
-
Business operations must update data atomically. To achieve atomicity, rely on the underlying database’s transaction mechanism.
-
Use the unit of work pattern when possible. A unit of work relies on the underlying database’s transactions; it also defers all updates to the end of the business operation, thus improving performance.
-
Don’t reuse database transactions or units of work between sections of the test. Each arrange, act, and assert section should have its own transaction or unit of work.
-
Execute integration tests sequentially. Parallel execution involves significant effort and usually is not worth it.
-
Clean up leftover data at the start of a test. This approach works fast, doesn’t result in inconsistent behavior, and isn’t prone to accidentally skipping the cleanup phase. With this approach, you don’t have to introduce a separate teardown phase, either.
-
Avoid in-memory databases such as SQLite. You’ll never gain good protection if your tests run against a database from a different vendor. Use the same database management system in tests as in production.
-
Shorten tests by extracting non-essential parts into private methods or helper classes:
- – For the arrange section, choose Object Mother over Test Data Builder.
- – For act, create decorator methods.
- – For assert, introduce a fluent interface.
-
The threshold for testing reads should be higher than that for writes. Test only the most complex or important read operations; disregard the rest.
-
Don’t test repositories directly, but only as part of the overarching integration test suite. Tests on repositories introduce too high maintenance costs for too few additional gains in protection against regressions.